InnoDB 的 Buffer Pool 分析
- 准备
- Buffer Pool 的结构
- Buffer Pool 相关参数
- Buffer Pool 的初始化
- Buffer Pool 的操作
- Buffer Pool 与 mini transaction
- Buffer Pool 的刷脏线程
- Buffer Pool 的自适应刷脏算法
- Buffer Pool 的 resize 过程
- 总结
- Q&A
准备
MySQL 版本: 8.0
用户使用数据库进行交互数据的,为了弥补磁盘与 CPU 的速度差距,一般都会采用 Cache 的方法. 在 MySQL 中,Buffer Pool 就是用来在内存中缓存数据 Page 的,而换入换出的算法采用的 LRU 算法.
Buffer Pool 的结构
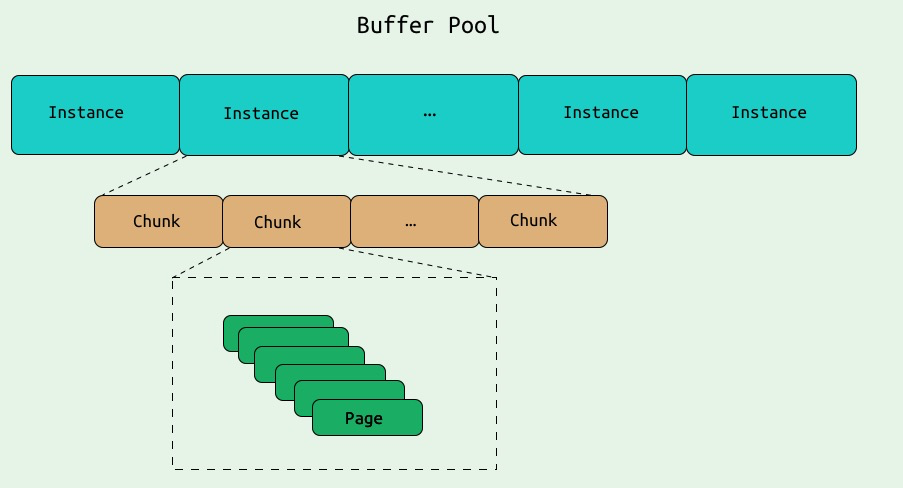
Buffer Pool 分为多个 Instance,具体的数量由设定的 size 决定,每个 Instance 包含多个 Chunk, 而 Chunk 又由多个 Page 组成. 将Buffer Pool 分为多个 Instance 的主要目的是为了减轻在高并发下锁争抢的压力.
Buffer Pool 相关参数
- innodb_buffer_pool_size: Buffer Pool 总的大小.
- innodb_buffer_pool_instances: Buffer Pool 中 Instance 的数量
- innodb_buffer_pool_chunk_size: Buffer Pool 中 Chunk 的大小, 默认为128M
Buffer Pool 中 Chunk 的大小可以自定义设置, 所以整个 Buffer Pool 的内存大小分配公式为n * innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances, n 为 Chunk 的数量. n 由 Buffer Pool 初始化阶段计算得出.
重要数据结构
每个 Instnace 即buf_pool_t主要包含以下结构 :
LRU: 淘汰算法 LRU 维护的链表flush_list: 被修改过的 Page 链表:free: 可用的 Page 链表page_hash: Hash 表, 避免查询的时候全量扫描LRU,可以通过space id和page no获取对应的 Page, 用于 Buffer Pool 的 Page 定位.withdraw: 用于缩小 Buffer Pool 的大小的过程中回收 Page 的链表.
Block 控制页结构:
1 | struct buf_block_t { |
Buffer Pool 中基本数据单元是buf_block_t,其中包括数据 Page 的元信息和数据等信息.
Buffer Pool 的初始化
buf_pool_init(): Buffer Pool 初始化入口函数buf_pool_create(): 初始化每个 Instance, 即初始化链表, 创建相关 mutex, 创建 Chunk 等.buf_chunk_init():- Chunk 的初始化, 使用
os_mem_alloc_large()分配内存 - 初始化
buf_block_t, 每一个 Block 包含block->frame数据页和block->page页信息管理 - 将每一个 Block 的 Page 结构即
block->page加入buf_pool->free链表.
- Chunk 的初始化, 使用
LRU_list分为 young 和 old 两部分, young 部分存储经常被使用的热点 Page,新读入的 Page 默认被加在 old 部分,只有满足一定条件后,才被移到 young 上,主要是为了预读的数据页和全表扫描污染 Buffer Pool。LRU_old作为一个游标来作为滑动的指针. 初始化阶段最后会设定 LRU 的比率参数:buf_LRU_old_ratio_update(100 * 3 / 8, FALSE). (LRU_old可以由buf_LRU_old_ratio_update()来更新)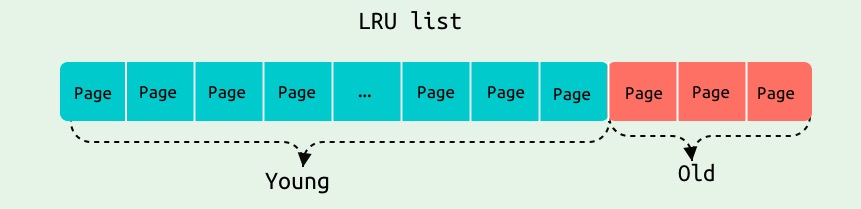
对于支持大页的 Linux 系统,InnoDB 使用shmget()申请共享内存, 而一般的 Linux 环境下使用mmap() (MAP_PRIVATE | OS_MAP_ANON) 申请指定大小的匿名页内存, 所以 Buffer Pool 的物理内存并不是启动时就全部分配,而是随着用户的使用动态分配物理内存.
Buffer Pool 的操作
当我们需要一个 Page 的时候会通过 Buffer Pool 申请, 具体的逻辑:
申请数据页 Block
buf_page_create()
通过
buf_pool_t的free_list中查找空闲的buf_block_t(buf_LRU_get_free_block()).假如
free_list中为空,即没有空闲的 Block, 则需要去LRU_list中寻找.LRU_list搜索策略:第一次搜索:
- 假如
buf_pool->try_LRU_scan被设置了true, 则通过lru_scan_itr从尾部往前搜索 100(BUF_LRU_SEARCH_SCAN_THRESHOLD) 个, 假如找到可以换出的 Page,放入free_list. - 假如没有找到可以换出的 Page, 则需要从
LRU_list尾部选择一个脏页进行刷盘, 即buf_flush_page(), 将其从page_hash和LRU中移除,然后放入free_list.
- 假如
第二次搜索:
- 需要搜索整个
LRU_list, 其余的策略与第一次搜索一致.
- 需要搜索整个
第三次搜索及以后:
- 仍然搜索整个
LRU_list但每次 Sleep 10ms
- 仍然搜索整个
当迭代次数超过 20 次,会打印一条频繁获取不到空闲 Page 的 log.
判断 Buffer Pool 是否存在该 Block, 假如存在直接返回.
否则需要通过
buf_page_init()初始化 Block 数据结构,将查找到的空闲的 Block 的信息替换为需要申请的这个 Block, 插入page_hash.将该 Block 加入
LRU_list的LRU_young部分(buf_page_make_young_if_needed()). 这里引入了时间的限制, 即假如第二次的访问时间必须超过buf_LRU_old_threshold_ms才会将其移动到 young 部分.
Buffer Pool 与 mini transaction
mini transaction 的start(), commit()操作过程其实就是与 Buffer Pool 进行交互,完成数据页的获取,读写和修改。所以我们可以通过 mini transaction 的操作过程来理解 Buffer Pool 的工作原理.
mini transaction 获取数据页
当 mini transaction 需要获取数据页时,首先会通过buf_page_get_gen()去 Buffer Pool 中获取:
buf_pool_get(page_id)通过 page id 获取所对应的 Buffer Pool 的 Instance. Instance 与 Page 的对应关系很简单:page_number >> 6然后求模:% srv_buf_pool_instances.buf_page_hash_get_low(buf_pool, page_id)通过前面提及的page_hash能快速的找到该 Page.假如 Page 在
LRU链表中处于 old 的部分,需要将其加至 young 部分.根据参数
rw_latch对 Page 加不同的锁.
Buffer Pool 读取物理文件
假如查找的 Page 不存在于 Buffer Pool 中,会从文件中读文件至 Buffer Pool 中(buf_read_page_low()):
buf_page_init_for_read()调用buf_page_init()在 Buffer Pool 中初始化一个 Page, 将该 Block 加至 old 部分.调用
fil_io()读取文件
mini transaction 提交脏页
当mini transaction 完成 Commit 的时候,假如该 Block 是第一次进行修改,会 Block 插入到 Buffer Pool 的flush_list,以后的修改在无需重复插入flush_list:
1 | // oldest_modification == 0 表示该 Page 是第一次修改的, 因为 oldest_modification 初始化为0 |
- 更新 Page 的
oldest_modification, 即 mtr 修改这个 Block 的起始 lsn - 添加到
buf_pool->flush_list链表
Buffer Pool 的刷脏线程
buf/buf0flu.cc:buf_flush_page_coordinator_thread()
Buffer Pool 提供多个 Flush 线程进行 Flush 操作,前面我们也提及到假如目前需要一个空闲的 Page, 用户线程会进行手工 Flush: 从 flush_list尾部选择一个 Page 进行 Flush 操作. 而我们下面分别介绍flush_list和LRU_list的刷脏线程buf_flush_page_coordinator_thread:
buf_flush_page_coordinator_thread是由用户创建的后台 Flush协调线程.刷盘主线程会新建 N 个
buf_flush_page_cleaner_thread线程, 即普通刷脏线程. 创建的普通刷脏线程会 wait 在page_cleaner->is_requested等待事件.进入主逻辑的
while循环(while (srv_shutdown_state == SRV_SHUTDOWN_NONE)):判断是否需要 Sleep:
1 | if (srv_check_activity(last_activity) || buf_get_n_pending_read_ios() || |
假如目前数据库有活跃的操作或者 Buffer Pool 的读任务, 则需要睡眠 1s, 让出 IO 和 CPU 资源.
假如目前的时间超过了上一次 Flush 设置的下一次刷盘时间
(ut_time_ms() > next_loop_time), 则设置OS_SYNC_TIME_EXCEEDED状态.否则不进入 Sleep
假如存在活跃的操作,则进入活跃刷新分支
if (srv_check_activity(last_activity)):通过
page_cleaner_flush_pages_recommendation()对每个 Buffer Pool 的 Instance 计算刷新脏页数量的建议.Flush协调线程 会调用
os_event_set(page_cleaner->is_requested)唤醒等待中的任务线程. 被唤醒的任务线程会调用pc_flush_slot()来做刷盘操作, 而 Flush 协调线程自身也会调用pc_flush_slot().pc_flush_slot()根据类型BUF_FLUSH_LRU或者BUF_FLUSH_LIST来选择对应的刷盘函数:BUF_FLUSH_LRU:buf_flush_LRU_list_batch()BUF_FLUSH_LIST:buf_do_flush_list_batch()遍历buf_pool->flush_list, 假如设置了srv_flush_neighbors=1即检查该 Page 的相邻的页是否允许 Flush, 之后通过buf_flush_ready_for_flush()选择符合 Flush 规则的 Page 进行刷盘buf_flush_page(). 使用fil_io()把 Page 写入文件.
后台刷新的协调线程会作为刷新调度协调的角色,它会确保每个 Buffer Pool 都已经开始执行刷新。如果哪个 Buffer Pool 的刷新请求还没有被处理,则由刷新协调线程亲自刷新,且直到所有的 Buffer Pool 都已开始进行了刷新.
LRU 淘汰规则
buf_flush_ready_for_replace():
1 | return (bpage->oldest_modification == 0 && |
oldest_modification == 0: 表示这个 Block 没有被修改.bpage->buf_fix_count == 0:buf_fix_count == 1表示有线程正在读该 Page.buf_page_get_io_fix(bpage) == BUF_IO_NONE: 表示该页目前没有任何 IO 操作.
Flush 规则
buf_flush_ready_for_flush():
1 | if (bpage->oldest_modification == 0 |
oldest_modification == 0: 表示这个 Block 没有被修改,即无须 Flushbuf_page_get_io_fix(bpage) != BUF_IO_NONE: 表示目前该 Page 存在操作,不允许进行 Flush 操作.
Buffer Pool 的自适应刷脏算法
涉及刷脏的变量
介绍刷脏算法之前,我们先来介绍几个关于刷脏的变量:
innodb_max_dirty_pages_pct
设定 Buffer Pool 中的脏页比, 在 MySQL 8.0.3 的版本中,默认值是 90%
innodb_max_dirty_pages_pct_lwm
用来指定”低水位”值,其表示使用预刷脏来控制脏页比例的百分比,防止脏页的百分比达到
innodb_max_dirty_pages_pct的值,innodb_max_dirty_pages_pct_lwm默认0,禁用预刷脏行为。innodb_io_capacity
设置 InnoDB 的后台线程允许每秒做多少次 IO
innodb_io_capacity_max
如果刷新活动落后,InnoDB 可以比 innodb_io_capacity 施加的限制更积极地刷新. innodb_io_capacity_max 定义了 InnoDB 后台任务在这种情况下每秒执行 IO 操作的上限.
刷脏算法
- 计算当前刷脏的平均速度
avg_page_rate:
1 | /* sum_pages: 上次刷脏的数量 |
- 计算 Redo Log 产生的平均速度
lsn_avg_rate
1 | /* |
根据
lsn_avg_rate计算刷脏的target_lsn遍历 Buffer Pool 的每一个 Instance 中的
flush_list, 将每一个 Block 的oldest_modifiaction与target_lsn比较.对每一个小于
target_lsn的 Block 进行计数,直到该 Block 大于target_lsn即 break 跳出
1 | /* 根据"脏页占比生成的刷脏数量建议 + Redo Log 产生的平均速度 avg_page_rate + Redo Log 产生的速度生成的刷脏数量建议 / 3 的平均值"来生成刷脏的数量建议. */ |
- 生成每一个 Instance 的刷脏数量建议:
1 | for (ulint i = 0; i < srv_buf_pool_instances; i++) { |
手动触发 Flush
set global innodb_buf_flush_list_now = 1手动强制进行flush_list的刷脏
innodb_lru_scan_depth
当free_list小于innodb_lru_scan_depth值时也会触发脏页刷新机制, 该值默认为 1024
Buffer Pool 的 resize 过程
Buffer Pool 提供了专门的一个线程buf_resize_thread来完成 resize 过程, 具体的操作函数是buf_pool_resize(),因为对于 Buffer Pool 中的 chunk 内存而言无法区分 free_list 或者 LRU_list, 所以引入了 withdraw_list 来置换 LRU_list 处于回收区间的 Page, resize 流程如下:
假如开启了 AHI, 需要关闭 AHI.
假如是缩小 Buffer Pool 的大小, 需要设置每个 Buffer Pool Instance 的
withdraw_target, 即设置回收的 Page 数目.buf_pool_withdraw_blocks()进行回收 Page 操作:首先从
buf_pool->free开始回收, 将 Page 从free_list中释放, 插入withdraw_list, 先回收 free_list 的目的是回收 LRU_list 中的 Page 时重分配 Page 时不会申请到处于回收区间的 Page.假如从
free_list中回收的 Page 数目没有达到要求, 则需要继续从lru_list中回收. 将脏页刷盘, 然后插入withdraw_list.
停止加载 Buffer Pool
假如回收的 Page 数目小于设定的
withdraw_target, 需要等待2, 4, 8, 最大 10s 的时间重复执行buf_pool_withdraw_blocks()加锁 Buffer Pool.
根据缩小或扩大的需求对 Buffer Pool Instance 的 Chunk 内存数量进行增删操作.
更新每个 Buffer Pool Instance 的大小
buf_pool->curr_size和 Chunk 数量buf_pool->n_chunks_new, Page 数目等.假如 Buffer Pool 的大小扩大了2倍或者缩小了2倍, 则需要新建新的
page_hash和zip_hash.释放 Buffer Pool 的
buf_pool_mutex和旧的page_hash.重新开启 AHI.
监控 Buffer Pool 的 resize 过程
用户可以通过Innodb_buffer_pool_resize_status查看 Buffer Pool 的 resize 过程中的状态:
1 | mysql> SHOW STATUS WHERE Variable_name='InnoDB_buffer_pool_resize_status'; |
总结
InnoDB 根据 Redo Log 的生成速度和当前的刷脏速度,使用一种自适应的算法来估计下一次的刷新速度,从而保持整个数据库的性能平缓, 不会突然因为脏页的增多从而影响数据库的吞吐, 通过刷脏的算法我们可以看到 InnoDB 设计的巧妙,不是简单的通过限定某一个脏页比来决定是否刷脏.
Q&A
- 当 Buffer Pool 的脏页比率超过了限制,触发自动刷脏机制,如何处理 Redo Log 的限制?
在正确的逻辑下,Redo Log 必须先于 Ditry Pages 落盘, 否则在发生 Crash 的情况下,会造成数据不一致. 为了保证这个条件,Buffer Pool 的刷脏机制会在刷盘前将 Page 的
newest_modification与log_sys->flushed_to_disk_lsn比较,假如大于,则需要主动触发 Redo Log 的落盘:
1 | const lsn_t flush_to_lsn = bpage->newest_modification; |