Linux 内核源码分析-物理内存的分配
准备
内核版本: 5.0
我们在物理内存组织形式谈论了Linux内核中物理内存的布局, 而物理内存的分配就由伙伴系统负责, 伙伴算法是一种非常简单的算法,但它因为其高效的分配策略, 成为了内核中物理内存的重要组成部分。
物理内存分配的数据结构
在物理内存中,我们依然使用内存页(Page)来作为分配的基本单元,物理内存被内核分为不同的ZONE,通过ZONE来直接管理内存页(Page):
ZONE的数据结构:
include/linux/mmzone.h
1 | struct zone { |
free_area管理该ZONE中所有的空闲Page链表和对应的连续内存区数量。而free_area是一个数组,里面每一个元素包含的连续内存区中Page的数量单位是不一样的,由阶(Order)决定, 每一个free_area连续内存区Page的数量是2^order:
- 第0个元素的连续内存区为1页(2^0)
- 第1个元素的连续内存区为2页(2^1)
- 第2个元素的连续内存区为4页(2^2)
- …
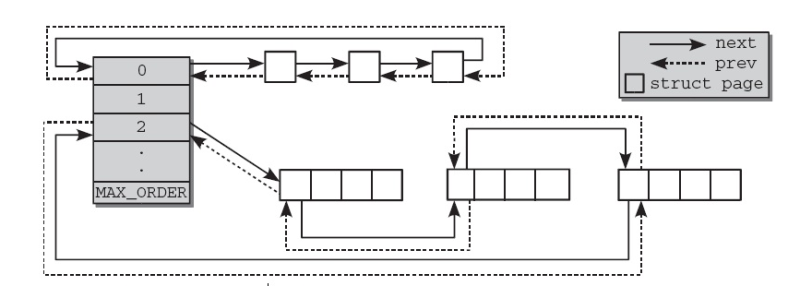
上图解释了一个ZONE的物理内存的伙伴系统,假如第1个free_area即(2^1)的连续内存区总共2页, 被分配使用了1页,还剩下1页空闲的物理内存页就会被挂靠在第1个free_area的内存链表.
假如该ZONE没有了空闲的内存Page,内核会尝试同一个节点的其他ZONE, 在NUMA架构, 接下来会尝试其他的NODE.
核心算法
在内存请页机制我们介绍了内核的请页机制, 当发现vma对应的Page不存在与物理内存中,就需要为vma分配一个物理页,而具体的分配算法就是我们介绍的伙伴算法.
核心函数是__alloc_pages_nodemask(): 在管理区链表zooelist中依次查找每个区,从中找到满足要求的区,然后分配2^order大小的Page. 如果所有的区都没有足够的空闲页面,则调用交换或刷脏的线程,把脏页交换或释放,以此来释放空间.
Slab分配器
上面介绍的伙伴算法每次至少分配2^0即1个Page, slab分配器用来处理每次分配小于一个Page的大小的物理内存.
slab结构的主要结构是: 缓冲区(cache) -> slab -> 对象(例如 struct unix_sock)
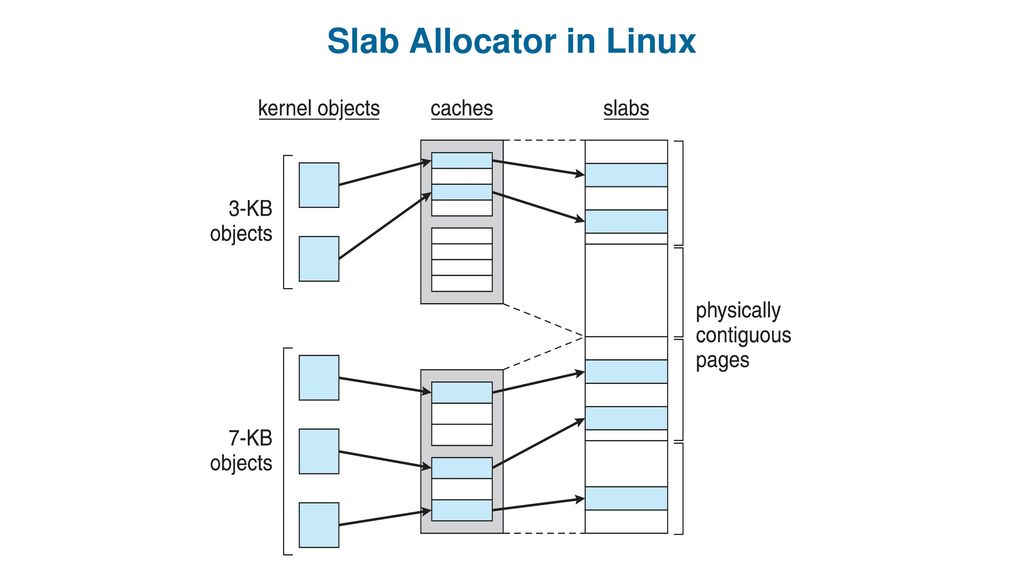
每个缓存都包含一个slabs的列表,这是一段连续的内存页. slab分配模式把被分配内存的对象放进缓冲区, 缓冲区的组织和管理和对象的命中率相关.slab的内存申请和释放都是只针对内核空间,用户空间的内存分配释放通过malloc和free. Slab分配器分配的内存来源于伙伴系统中管理的Page.
查看Buddy系统内存分配
1 | : echo m > /proc/sysrq-trigger |
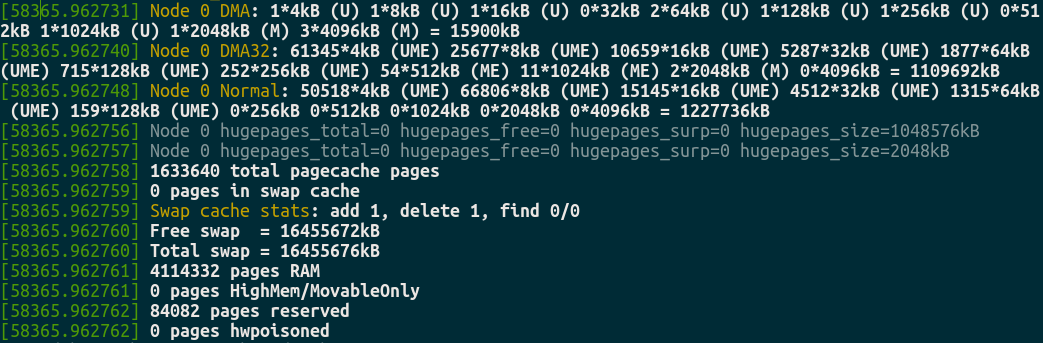
我们可以看到本机不属于NUMA架构, 只有一个Node 0, 而Normal的内存分配情况如下:1
2
3
4
5
6
7
8
9
10
1150518*4kB (UME)
66806*8kB (UME)
15145*16kB (UME)
4512*32kB (UME)
1315*64kB (UME)
159*128kB (UME)
0*256kB
0*512kB
0*1024kB
0*2048kB
0*4096kB = 1227736kB