背景
网上关于Raft的博文已经足够多了,这里只记录个人学习Raft协议中一些关键的地方。参考的资料是Raft和作者的PhD的Raft论文还有Raft的C++实现floyd。
Raft协议
Raft协议用来保证数据的一致性,它是根据Leadership的方法来完成日志的复制,Leader接受来自Client的数据,然后将数据复制到其他的Server,如果一个Leader失败或者断开连接,一个新的Leader将会选举出来。Raft基本上可以分为三个子问题:
- Leader election
- Log replication
- Safety
Raft基本知识
先来介绍一些Raft的基本知识。首先,Raft算法中维护三种状态:Leader,Follower和Candidate。当具体操作时,集群中有一个Leader,剩下的节点均为Followers。Followers只响应来自Leader或者Candidate的请求,而Leader响应来自Client的请求,如果有Client请求发送至了Followers,会被转发至Leader。
Raft协议将一个Leader的任期称作一个Term,Term是任意长度的时间片,Term的Number是顺序递增的。
Raft协议通信主要使用两种类型的RPC:
- AppendEntries RPC:复制Log和发送心跳
- RequestVote RPC:Candidate发起投票
Leader election
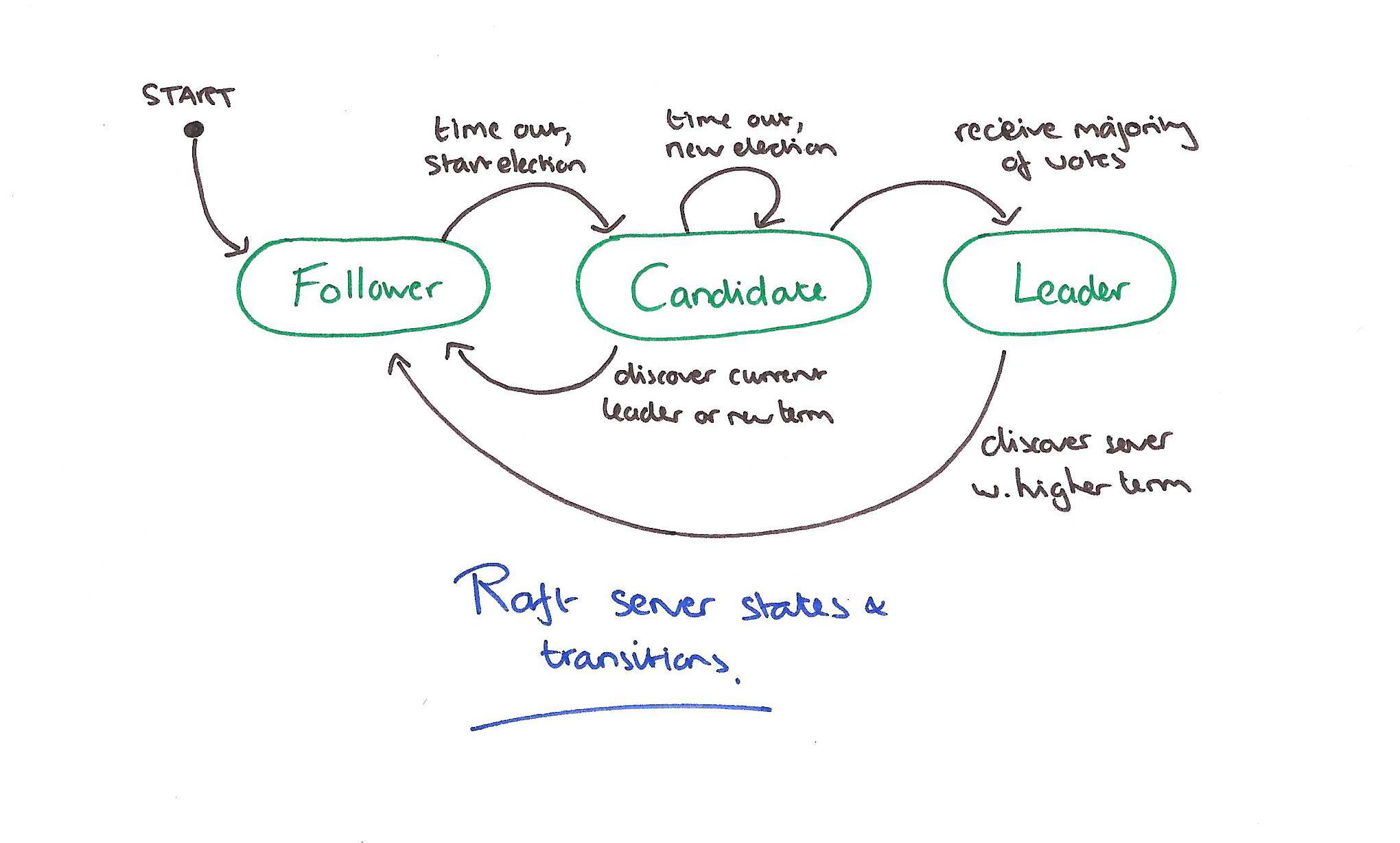
Raft协议利用心跳机制来触发选举,当集群中的Server启动时,它们都是Followers状态。当某一个Folloer到达了自己的Election timeout,它就会发起选举:
- 自增Term的Number
- 将自己的状态从Follower转为Candidate
- 投票给自己
- 发送
RequestVote RPC给其他的所有节点
一个Candidate保持这种状态直到三种情况发生:
- 它赢得了选举
- 其他的Candidate节点赢得了选举
- 没有任何Candidate节点赢得了选举
如果一个Candidate在一个Term内获得了超过半数的投票,它就赢得了选举,成为了这个Term任期内的Leader。每一个节点在一个Term内只能投票给一个Candidate,秉承先来先投的原则,并且Raft协议中每一个节点使用一个随机的限定区间的election timeout(150-300ms)。这两个规则确保了在大部分情况下只有一个Candidate可以赢得选举,保证分裂投票的最大可能的降低发生概率。当一个Candidate成为了Leader之后,它就会发送心跳包给其他节点防止开始新的选举。
Log replication
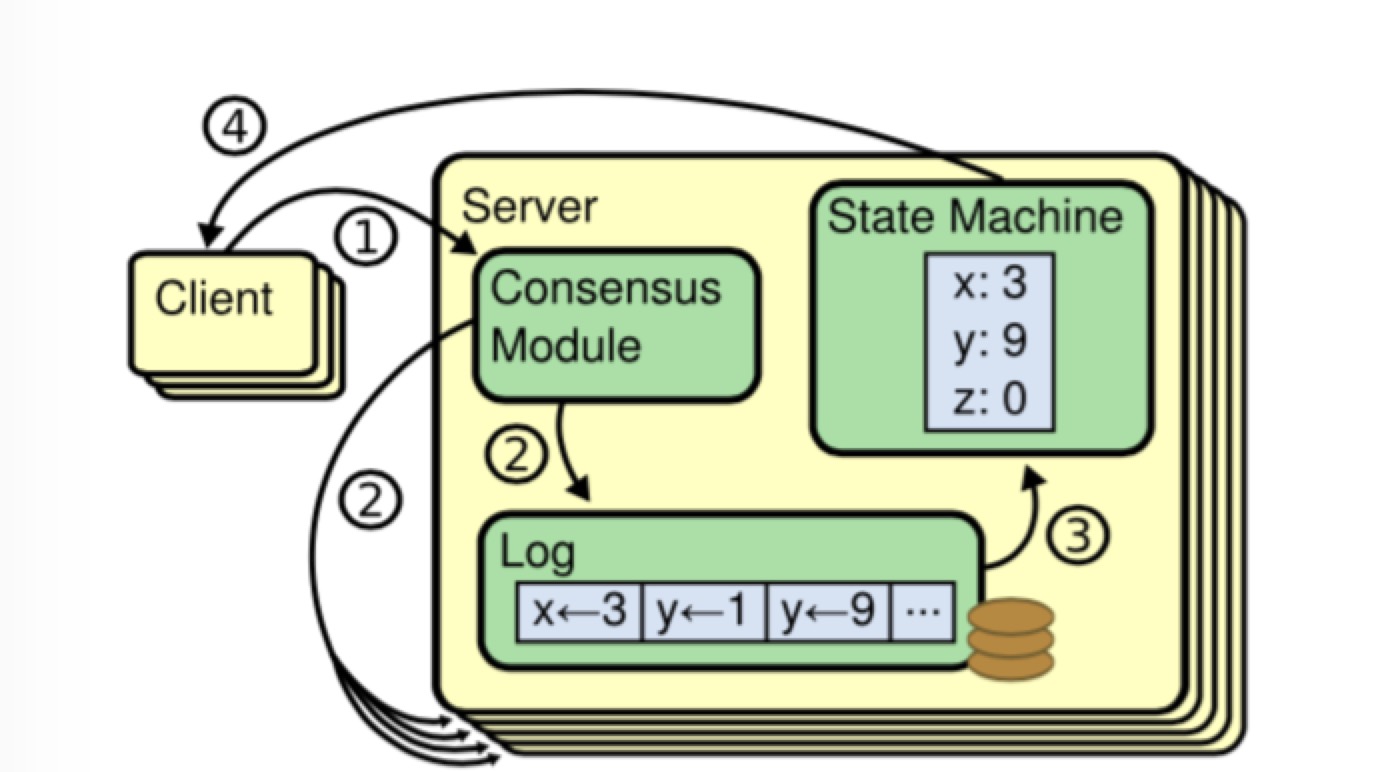
- Leade收到一条来自Client的命令,写入本地的Log,之后调用
AppendEntries RPC并行的向所有Follow节点发送该Log - 当Leader发送一个
AppendEntries RPC时,会包括新的Entry Log之前的那条Entry Log的Term和Index,Follower会根据前一条Entry Log的Term和Index做安全性的检查,如果没有发现该条Log,它会拒绝新的Entry Log。 - 如果这条Entry Log被大部分节点接受,这条Log就会被Apply至状态机,这样的一条Log称为Committed。Leader将执行结果返回给Client。
Raft的Log replication要求保证一下性质:
- 如果两个log entry有相同的index和term,那么它们存储相同的指令。
- 如果两个log entry在两份不同的日志中,并且有相同的index和term,那么它们之前的log entry是完全相同的。
在某些意外情况下,比如Leader的崩溃退出,有可能导致Leader和Followers的日志不一致的情况,双方通过 AppendEntries RPC 来做一些一致性的检查:
- Leader为所有的Followers维护一个
nextIndex[]用来表示下一条需要发送给Follower的Log的Index,AppendEntries RPC会带一个新的Log和上一个Log的Index和Term。如果双方的Log不一致,AppendEntries RPC的一致性检查将会失败,Leader会减一次nextIndex然后重发AppendEntries RPC直到Follower和Leader的日志成功匹配。
Safety
Election restriction
发起投票的 RequestVote RPC 包括Candidate的日志信息: Index和Term,假如Follower的日志信息比Candidate,就会拒绝投票。Raft限制新的Leader拥有最大的Term和最新的Log信息。
Committing entries fron previous terms
Raft限制Leader只能对自己当前任期内的Term的Log做提交Commit。
Cluster membership changes
Raft配置信息变更中存在三个状态:
- Cold即旧的配置信息生效的状态
- Cold,new即新旧配置文件都生效的状态
- Cnew即新的配置文件生效的状态
在Raft设计中,成员变更也是作为一条Log,Leader首先创建一条关于Cold,new的配置信息变更的Log,当被Cold配置中的大部分节点和Cnew配置中的大部分节点接受,然后再创建一条Cnew配置信息的Log,保证Cnew配置中的大部分节点接受。
配置信息中有三个子问题需要注意:
- 当新的空节点加入集群后,它有可能长时间处在追赶Log的过程中,从而导致配置变更的Log无法生效。Raft为此引入了一个新的节点状态
non-voting members(Leader发送日志给新的空节点,但它们不被考虑在大多数的条件范围内),直到新的节点追上了集群,才开始做配置变更。 - 目前整个集群的Leader可能不在新的配置文件中。在这种情况下,当Cnew配置信息变更Log被Committed之后,它会将自己的状态降为Follower.
- 移除的节点干扰集群。因为这些节点无法收到心跳,所以超时之后会发起选举。因为发起选举前会自增Term,所以会造成现在集群内的Leader失效。为了防止这种情况,Raft限制当一个Follower节点会在收到来自Leader的选举超时周期内拒绝别的节点发来的
RequestVote RPC。