概述
版本:v5.15.10
之前我们分析了RocksDB的默认写入方式,而在 options 可以设置 enable_pipelined_write, 即pipelined(流水线)写入方式,默认的写入方式中,一个batch的需要完成WAL之后,再完成Memtable的写入才选出下一个Leader.而Pipelined写入中不需要等待Memtable写入完成,即当WAL写入完成之后,即可选出下一个Leader继续完成下一个batch的写入从而达到Pipelined的效果.
具体实现
Pipelined的写入在默认的写入方式中进行跳转,我们直接来看Pipelined的具体实现 db/db_impl_write.cc:PipelinedWriteImpl():
Status DBImpl::PipelinedWriteImpl(const WriteOptions& write_options,
WriteBatch* my_batch, WriteCallback* callback,
uint64_t* log_used, uint64_t log_ref,
bool disable_memtable, uint64_t* seq_used) {
PERF_TIMER_GUARD(write_pre_and_post_process_time);
StopWatch write_sw(env_, immutable_db_options_.statistics.get(), DB_WRITE);
WriteContext write_context;
// 新建一个writer
WriteThread::Writer w(write_options, my_batch, callback, log_ref,
disable_memtable);
// 将新建的writer加入batch队列中
write_thread_.JoinBatchGroup(&w);
// 判断状态是否为STATE_GROUP_LEADER, 即一个batch的leader
if (w.state == WriteThread::STATE_GROUP_LEADER) {
// ...
// leader选择其他writer加入整个batch中
last_batch_group_size_ =
write_thread_.EnterAsBatchGroupLeader(&w, &wal_write_group);
const SequenceNumber current_sequence =
write_thread_.UpdateLastSequence(versions_->LastSequence()) + 1;
size_t total_count = 0;
size_t total_byte_size = 0;
// ...
// 需要写入WAL
if (w.ShouldWriteToWAL()) {
// ...
// 写入WAL
w.status = WriteToWAL(wal_write_group, log_writer, log_used,
need_log_sync, need_log_dir_sync, current_sequence);
}
// batch的Leader完成WAL的写入后退出,稍后会介绍该该函数
write_thread_.ExitAsBatchGroupLeader(wal_write_group, w.status);
}
// 假如状态为STATE_MEMTABLE_WRITER_LEADER, 即作为memtable的batch中的Leader
WriteThread::WriteGroup memtable_write_group;
if (w.state == WriteThread::STATE_MEMTABLE_WRITER_LEADER) {
PERF_TIMER_GUARD(write_memtable_time);
assert(w.status.ok());
// leader选择其他的writer加入整个batch
write_thread_.EnterAsMemTableWriter(&w, &memtable_write_group);
if (memtable_write_group.size > 1 &&
immutable_db_options_.allow_concurrent_memtable_write) {
// 假如允许并发写memtable,leader唤醒其他writer来完成各自的memtable写入任务
write_thread_.LaunchParallelMemTableWriters(&memtable_write_group);
} else {
// 否则由memtable的batch中所设置的leader来完成memtable的写入
memtable_write_group.status = WriteBatchInternal::InsertInto(
memtable_write_group, w.sequence, column_family_memtables_.get(),
&flush_scheduler_, write_options.ignore_missing_column_families,
0 /*log_number*/, this, seq_per_batch_);
versions_->SetLastSequence(memtable_write_group.last_sequence);
write_thread_.ExitAsMemTableWriter(&w, memtable_write_group);
}
}
// 假如状态为STATE_PARALLEL_MEMTABLE_WRITER,即memtale的batch中的writer
if (w.state == WriteThread::STATE_PARALLEL_MEMTABLE_WRITER) {
assert(w.ShouldWriteToMemtable());
ColumnFamilyMemTablesImpl column_family_memtables(
versions_->GetColumnFamilySet());
// memtable的写入
w.status = WriteBatchInternal::InsertInto(
&w, w.sequence, &column_family_memtables, &flush_scheduler_,
write_options.ignore_missing_column_families, 0 /*log_number*/, this,
true /*concurrent_memtable_writes*/);
// 查看memtable的batch中的所有writers是否已经全部完成了写入
if (write_thread_.CompleteParallelMemTableWriter(&w)) {
// 假如全部完成了写入,则以memtable的batch的leader身份设置其他的writer状态,
// 并选择下一个memtabl的batch的leader.
MemTableInsertStatusCheck(w.status);
versions_->SetLastSequence(w.write_group->last_sequence);
write_thread_.ExitAsMemTableWriter(&w, *w.write_group);
}
}
if (seq_used != nullptr) {
*seq_used = w.sequence;
}
assert(w.state == WriteThread::STATE_COMPLETED);
return w.FinalStatus();
}来分析 ExitAsBatchGroupLeader():
void WriteThread::ExitAsBatchGroupLeader(WriteGroup& write_group,
Status status) {
Writer* leader = write_group.leader;
Writer* last_writer = write_group.last_writer;
assert(leader->link_older == nullptr);
// Propagate memtable write error to the whole group.
if (status.ok() && !write_group.status.ok()) {
status = write_group.status;
}
// 假如是Pipelined写入方式
if (enable_pipelined_write_) {
// Notify writers don't write to memtable to exit.
for (Writer* w = last_writer; w != leader;) {
Writer* next = w->link_older;
w->status = status;
// 如果无需写入memtale, 则设置其他的writer状态为STATE_COMPLETED后退出
if (!w->ShouldWriteToMemtable()) {
CompleteFollower(w, write_group);
}
w = next;
}
// 假如Leader也无需写入memtable, 设置自己的状态为STATE_COMPLETED后退出
if (!leader->ShouldWriteToMemtable()) {
CompleteLeader(write_group);
}
Writer* next_leader = nullptr;
// 选出下一个batch的leader
// 首先判断等待队列中是否有新来的writer, 假如没有,则插入一个dummy(空)的write至 // 等队列
Writer dummy;
Writer* expected = last_writer;
bool has_dummy = newest_writer_.compare_exchange_strong(expected, &dummy);
if (!has_dummy) {
// 假如插入失败,即目前等待队列已经存在新来的writer,则设置下一个batch的leader
next_leader = FindNextLeader(expected, last_writer);
assert(next_leader != nullptr && next_leader != last_writer);
}
// leader判断batch的数量,假如大于0,则将自己连同其他的writer合并进memtable的
// batch队列中
if (write_group.size > 0) {
if (LinkGroup(write_group, &newest_memtable_writer_)) {
// The leader can now be different from current writer.
SetState(write_group.leader, STATE_MEMTABLE_WRITER_LEADER);
}
}
// 假如dummpy插入成功,即目前不存在新来的writer,则以dummy为基准,选择下一个batch
// 的leader
if (has_dummy) {
assert(next_leader == nullptr);
expected = &dummy;
bool has_pending_writer =
!newest_writer_.compare_exchange_strong(expected, nullptr);
if (has_pending_writer) {
next_leader = FindNextLeader(expected, &dummy);
assert(next_leader != nullptr && next_leader != &dummy);
}
}
// 假如下一个batch的leader设置成功
if (next_leader != nullptr) {
next_leader->link_older = nullptr;
// 将其唤醒,并设置状态为STATE_GROUP_LEADER
SetState(next_leader, STATE_GROUP_LEADER);
}
// leader等待唤醒
AwaitState(leader, STATE_MEMTABLE_WRITER_LEADER |
STATE_PARALLEL_MEMTABLE_WRITER | STATE_COMPLETED,
&eabgl_ctx);
} else {
// 默认的写入方式
// ...
}
}关于Pipelined的一个Bug
官方修复过一个关于Pipelined的Bug, 我们在上面的 ExitAsBatchGroupLeader() 中可以看到每次batch的完成之后在查找下个Leader之前会插入一个 dummy 的writer.
至于为什么要插入这个 dummy,我们来梳理一下RocksDB的Pipelined中查找下个Leader的一个关键逻辑: Pipelined会从最新的writer回溯至本次batch的 last_writer, 将 last_writer 之后的writer置为下一个batch的leader, 而在某些特别的边界情况下,last_writer 的指针地址与之后的batch中某一个writer地址相同,所以 last_writer 与其之间的writer都会被忽略,从而导致阻塞.
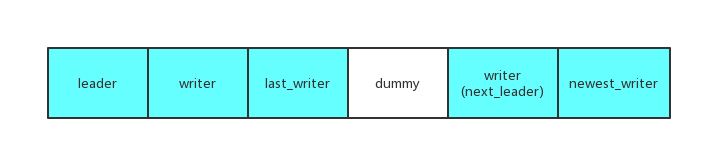
解决方法就是在中间放置一个 dummy, 抛弃之前与 last_writer 比较的逻辑,改为每次与 dummy 进行比较.