InnoDB 事务分析-MVCC
MVCC
MySQL版本: 8.0
上一篇InnoDB的事务分析-Undo Log我们分析了 Undo Log 的结构,在 InnoDB 的事务并发控制中采用的是 MVCC 的方法,即多版本控制。当一个事务修改表中数据的某一行时,将旧版本的数据插入 Undo Log 中,假如事务需要回滚操作时,Undo Log 则被用于还原旧版本数据. 而在用户需要根据当前的事务级别读取正确的数据时,利用 MVCC 可以保证事务在并行发生时,在一定隔离级别前提下,在某个事务中能实现一致性读,InnoDB提供四种事务级别, READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, 和 SERIALIZABLE. 默认的事务级别是 REPEATABLE READ. InnoDB 的事务系统严格遵守 2PL 加锁协议.
概念
在了解具体细节之前,我们先来介绍几点事务的概念和SQL标准定义的事务隔离级别:
事务是数据库关系系统中的一系列操作的一个逻辑单位.
现象
-
Dirty Reads: 一个事务还未提交,另外一个事务访问此事务修改的数据,并使用,读取了事务中间状态数据. 脏读,强调的是主事务读取了一个不存在(因回滚而不存在)的数据.
-
Nonrepeatable Reads:一个事务读取同一条记录两次(第一次读确认数据存在),由于两次读取间隔期间,另一个事务对数据进行了修改,使得事务两次读取的结果不一致.
-
Phantoms: 事务 A 第一次读取与搜索条件相匹配的若干行不存在. 事务 B 以插入或删除行等方式来修改事务 A 的结果集,然后再提交, 导致事务 A 读取了与第一次结果不一致的数据集.
事务隔离级别
-
Read Uncommitted: 这是最低的事务隔离级别,所有事务都可以看到其他未提交事务的执行结果,存在脏读.
-
Read Committed: 这个级别保证事务内读到的每一条数据行都是已经被commit的,不会存在脏读.
-
Repeatable Read: 可重复读。在同一个事务内的查询都是事务开始时刻一致的.
-
Serializable: 串行化,强制事务之间进行排序,不会互相冲突.
隔离级别与现象的矩阵图如下:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 未提交读 | 可能发生 | 可能发生 | 可能发生 |
| 已提交读 | 不可能发生 | 可能发生 | 可能发生 |
| 可重复读 | 不可能发生 | 不可能发生 | 可能发生 |
| 串行化 | 不可能发生 | 不可能发生 | 不可能发生 |
不可重复读和幻读的区别
不可重复读的现象是用户第一次读取,返回结果集 a, 而第二次读取返回结果 a’, 即数据发生了变更. 而 a’ 数据确实由一个已经 committed 的事务修改. 不可重复读现象需要隔离级别为 Repeatable Read 来规避. 在 InnoDB 中使用 MVCC 机制实现.
通常来说, MVCC 的多版本控制并不能保证在 RR 隔离级别下完全避免幻读, 但 InnoDB 通过 MVCC + Next key lock 的方式来保证在 RR 隔离级别下避免部分场景下幻读. 官方关于幻读文档
事务控制语句
BEGIN开始一个事务ROLLBACK事务回滚COMMIT事务确认SET AUTOCOMMIT=0禁止自动提交SET AUTOCOMMIT=1开启自动提交
在 MySQL 中,默认开启 AUTOCOMMIT 即执行的每一条 SQL 语句都是原子的.
数据结构
trx_sys_t
trx_sys_t 是整个事务的管理系统,包括 MVCC 的控制模块和数据库所有的活跃事务,以及回滚段 Rollback Segments 管理.
/** The transaction system central memory data structure. */
struct trx_sys_t {
/* ... */
MVCC *mvcc; /*!< Multi version concurrency control manager */
/* ... */
volatile trx_id_t max_trx_id; /* 下一个事务被分配的ID */
std::atomic<trx_id_t> min_active_id; /* 最小的活跃事务ID */
trx_id_t rw_max_trx_id; /* 最大的活跃事务ID */
Rsegs rsegs; /* 回滚段 */
}MVCC
/** The MVCC read view manager */
class MVCC {
private:
view_list_t m_free; /* 空闲即可以被重复使用的 Read View 的链表 */
view_list_t m_views; /* 活跃或者已经关闭的 Read View 的链表 */
};Read View
class ReadView {
/* ... */
private:
trx_id_t m_low_limit_id; /* 大于等于这个 ID 的事务均不可见 */
trx_id_t m_up_limit_id; /* 小于这个 ID 的事务均可见 */
trx_id_t m_creator_trx_id; /* 创建该 Read View 的事务ID */
trx_id_t m_low_limit_no; /* 事务 Number, 小于该 Number 的 Undo Logs 均可以被 Purge */
ids_t m_ids; /* 创建 Read View 时的活跃事务列表 */
m_closed; /* 标记 Read View 是否 close */
}Read View 的作用是利用 consistent read view 提供某一时刻事务系统的快照, 后续数据的读通过 Read View 来完成对应的事务可见性. Read View 中的 m_low_limit_id 和 m_up_limit_id 分别用来判断事务的可见性. m_low_limit_no 用来判断是否可以被 Purge, m_ids 包括当前 Read View 的活跃事务链表, 当事务需要读取一条 Record 时,会通过 Record 中 trx id 和 m_ids 中的活跃事务链表对比,判断当前 Record 是否对当前事务可见.
InnoDB 的事务流程
事务相关 SQL 语句
START TRANSACTION
[transaction_characteristic [, transaction_characteristic] ...]
transaction_characteristic: {
WITH CONSISTENT SNAPSHOT
| READ WRITE
| READ ONLY
}
BEGIN [WORK]
COMMIT [WORK] [AND [NO] CHAIN] [[NO] RELEASE]
ROLLBACK [WORK] [AND [NO] CHAIN] [[NO] RELEASE]
SET autocommit = {0 | 1}事务启动
我们以 WITH CONSISTENT SNAPSHOT 为例,即隔离级别 REPEATABLE READ:
用户开启事务执行 begin 后, sql/sql_parse.cc 解析SQL语句进入 trans_begin():
case SQLCOM_BEGIN:
if (trans_begin(thd, lex->start_transaction_opt)) goto error;
my_ok(thd);
break;事务启动的主要函数是 trans_begin():
-
检查当前用户连接
thd是否存在活跃事务, 假如没有就分配一个trx_t并初始化 -
启动该事务并将状态置为
TRX_STATE_ACTIVE -
InnoDB 只有读写/写事务分配 trx->id,而单纯的读事务 trx->id = 0
-
假如事务隔离级别为 TRX_ISO_REPEATABLE_READ,即需要在启动时为事务分配 Read View, 并初始化 Read View 中的几个值:
void ReadView::prepare(trx_id_t id) { ut_ad(mutex_own(&trx_sys->mutex)); /* id 即为创建该 Read View 的事务ID. */ m_creator_trx_id = id; /* 将 m_low_limit_no, m_low_limit_id 和 m_up_limit_id 初始化为当前 trx_sys 最大的事务ID. */ m_low_limit_no = m_low_limit_id = m_up_limit_id = trx_sys->max_trx_id; if (!trx_sys->rw_trx_ids.empty()) { /* 假如当前 trx_sys 的活跃事务列表不为空,则将其拷贝至 m_ids. * 并在这个过程中更新 m_up_limit_id = m_ids.front(), * 即将 m_up_limit_id 更新为当前活跃事务列表中 trx_id 最小的一个. */ copy_trx_ids(trx_sys->rw_trx_ids); } else { /* 否则清空 Read View 的活跃事务列表. */ m_ids.clear(); } ut_ad(m_up_limit_id <= m_low_limit_id); if (UT_LIST_GET_LEN(trx_sys->serialisation_list) > 0) { const trx_t *trx; trx = UT_LIST_GET_FIRST(trx_sys->serialisation_list); /* serialisation_list 为当前 trx_sys 正在 commit 的活跃事务, 选择最小的 trx->no 赋值于 m_low_limit_no. */ if (trx->no < m_low_limit_no) { m_low_limit_no = trx->no; } } ut_d(m_view_low_limit_no = m_low_limit_no); /* m_closed 设为 false. */ m_closed = false; } -
将 Read View 添加至 MVCC 管理单元中的
MVCC::m_views
事务内的查询
当我们事务中执行查询语句例如 select 语句,获取对应的 Record 之后,我们需要判断该 Record 是否满足事务约束的可见性:
bool lock_clust_rec_cons_read_sees(
const rec_t *rec, /*!< in: user record which should be read or
passed over by a read cursor */
dict_index_t *index, /*!< in: clustered index */
const ulint *offsets, /*!< in: rec_get_offsets(rec, index) */
ReadView *view) /*!< in: consistent read view */
{
/* ... */
/* 获取该条 Record 的trx_id */
trx_id_t trx_id = row_get_rec_trx_id(rec, index, offsets);
/* 判断可见性 */
return (view->changes_visible(trx_id, index->table->name));
}changes_visible() 判断可见性
changes_visible() 的返回结果 true 代表可见,false 代表不可见.
/* storage/innobase/include/read0types.h */
bool changes_visible(trx_id_t id, const table_name_t &name) const
MY_ATTRIBUTE((warn_unused_result)) {
ut_ad(id > 0);
/* 假如 trx_id 小于 Read View 限制的最小活跃事务ID m_up_limit_id 或者等于正在创建的事务ID
* m_creator_trx_id 即满足事务的可见性. */
if (id < m_up_limit_id || id == m_creator_trx_id) {
/* 可见. */
return (true);
}
/* 检查 trx_id 是否有效. */
check_trx_id_sanity(id, name);
if (id >= m_low_limit_id) {
/* 假如 trx_id 大于等于最大活跃的事务ID m_low_limit_id, 即不可见. */
return (false);
} else if (m_ids.empty()) {
/* 假如目前不存在活跃的事务,即可见. */
return (true);
}
const ids_t::value_type *p = m_ids.data();
/* 利用二分查找搜索活跃事务列表, 当 trx_id 在 m_up_limit_id 和 m_low_limit_id 之间
* 如果 id 在 m_ids 数组中, 表明 ReadView 创建时候,事务处于活跃状态,因此记录不可见. */
return (!std::binary_search(p, p + m_ids.size(), id));
}事务可见性示意图

- 大于等于 m_low_limit_id 均不可见.
- 小于 m_up_limit_id 均可见
- 假如存在于活跃事务列表中, 则不可见. 反之即可见.
假如我们当前查找的 Record 不满足事务的可见性,我们需要通过 Undo Log 回溯该 Record 在 MVCC 中满足可见性的数据版本:
调用 row_sel_build_prev_vers_for_mysq() 通过 Undo Log 来回溯 Record 之前的数据版本
-
获取 Record 的回滚段指针 roll_ptr:
roll_ptr = row_get_rec_roll_ptr(rec, index, offsets); -
获取 Record 的事务 ID:
rec_trx_id = row_get_rec_trx_id(rec, index, offsets); -
获取对应的 Undo Record 内容:
/* 解析 roll_ptr 指针内容. */ trx_undo_decode_roll_ptr(roll_ptr, &is_insert, &rseg_id, &page_no, &offset); /* 获取对应的 Undo Tablespace. */ space_id = trx_rseg_id_to_space_id(rseg_id, is_temp); bool found; const page_size_t &page_size = fil_space_get_page_size(space_id, &found); ut_ad(found); mtr_start(&mtr); /* 获取对应的 Undo Page. */ undo_page = trx_undo_page_get_s_latched(page_id_t(space_id, page_no), page_size, &mtr); /* 通过 offset 获取对应的 Undo Record. */ undo_rec = trx_undo_rec_copy(undo_page + offset, heap); mtr_commit(&mtr);
事务的提交
提交流程:
----------------------
| innobase_commit_low() |
-----------------------
|
|
| ------------------------
--> | trx_commit_for_mysql() |
------------------------
|
|
| --------------
--> | trx_commit() |
--------------
|
|
| ------------------
--> | trx_commit_low() |
------------------
|
|
| -----------------------------------
--> | trx_write_serialisation_history() |
| -----------------------------------
| |
| |
| | ------------------------------------------------------------------
| --> | trx_undo_set_state_at_finish(trx->rsegs.m_redo.insert_undo, mtr) |
| | ------------------------------------------------------------------
| |
| |
| | --------------------------------
| --> | trx_serialisation_number_get() |
| | --------------------------------
| |
| |
| | ------------------------------------------------------------------
| --> | trx_undo_set_state_at_finish(trx->rsegs.m_redo.update_undo, mtr) |
| | ------------------------------------------------------------------
| |
| | ---------------------------
| --> | trx_undo_update_cleanup() |
| ---------------------------
|
| ------------------------
--> | trx_commit_in_memory() |
------------------------当用户执行事务 commit 时, 会通过 innobase_commit_low() 一路调用.
trx_write_serialisation_history()用来处理事务过程中的 Undo Log 收尾工作,trx_undo_set_state_at_finish()用来更新 Insert 和 Update 操作产生的 Undo Log 状态:
page_t *trx_undo_set_state_at_finish(
trx_undo_t *undo, /*!< in: undo log memory copy */
mtr_t *mtr) /*!< in: mtr */
{
trx_usegf_t *seg_hdr;
trx_upagef_t *page_hdr;
page_t *undo_page;
ulint state;
ut_a(undo->id < TRX_RSEG_N_SLOTS);
/* 获取 Undo Log 的 Header Page. */
undo_page = trx_undo_page_get(page_id_t(undo->space, undo->hdr_page_no),
undo->page_size, mtr);
seg_hdr = undo_page + TRX_UNDO_SEG_HDR;
page_hdr = undo_page + TRX_UNDO_PAGE_HDR;
if (undo->size == 1 && mach_read_from_2(page_hdr + TRX_UNDO_PAGE_FREE) <
TRX_UNDO_PAGE_REUSE_LIMIT) {
/* 假如 Undo Log 所用的 Page 数量为1, 并且所使用的的空间不足 3/4 即可以被重用. */
state = TRX_UNDO_CACHED;
} else if (undo->type == TRX_UNDO_INSERT) {
/* 对于 Insert 操作产生的 Undo Log 可以直接释放. */
state = TRX_UNDO_TO_FREE;
} else {
/* 对于 Update 操作产生的 Undo Log 需要在合适的时机才能 Purge. */
state = TRX_UNDO_TO_PURGE;
}
undo->state = state;
/* 将状态写入 Undo Header Page. */
mlog_write_ulint(seg_hdr + TRX_UNDO_STATE, state, MLOG_2BYTES, mtr);
return (undo_page);
}trx_serialisation_number_get()会更新当前trx->no, 待 commit 的事务插入链表trx_sys->serialisation_list, 事务对应的回滚段插入purge_sys->purge_queue:
/* 更新为当前最大的 trx id. */
trx->no = trx_sys_get_new_trx_id();trx_commit_in_memory()会释放当前事务的 Read View 和事务过程中所持有的 table lock 和 record lock (2PL).
事务的回滚
事务回滚的入口函数是 innobase_rollback(), 过程如下:
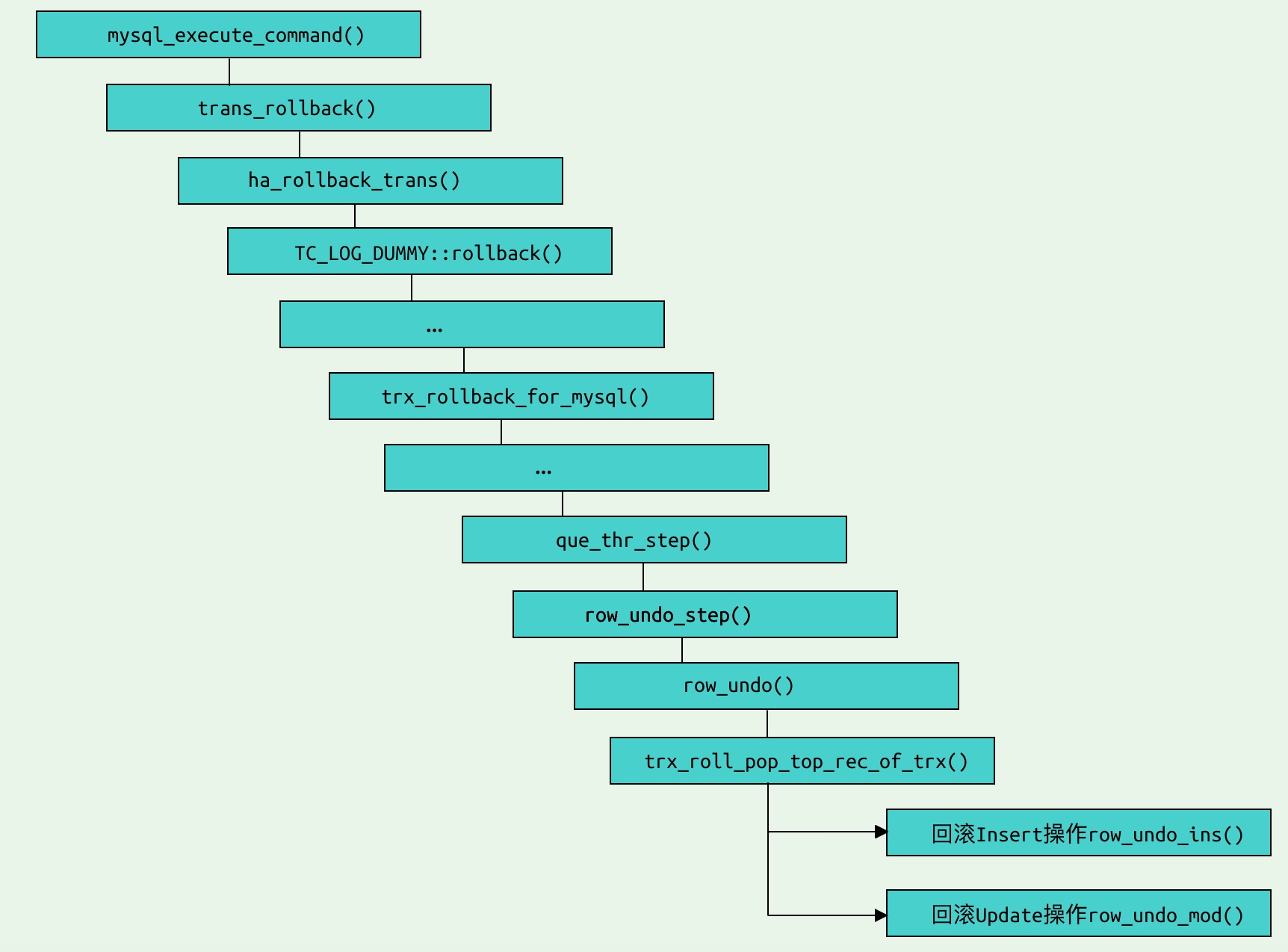
InnoDB 的事务回滚是通过 Undo Log 实现的, 通过 roll_ptr 选择回滚最后一条 Undo Log (trx_roll_pop_top_rec_of_trx), 根据数据的类型不同 Update 或者 Insert 选择不同的回滚方式, 假如是 Insert 操作, 则调用 row_undo_ins() 回滚, 直接删除主键索引和二级索引上的数据(btr_cur_optimistic_delete()), Update 操作选择 row_undo_mod() 将更新过的数据利用 Undo Log 还原, 与数据直接写入原理相同(btr_cur_optimistic_insert()).
事务的 Undo Log 回滚之后会调用 trx_rollback_finish(), 而 trx_rollback_finish() 依然会调用 trx_commit() 进行事务过程中获取的锁的释放的操作.
我们将上面提及的数据结构 trx_sys_t, MVCC 和 Read View 结合来看: trx_sys_t 管理整个 MySQL 数据库的事务元信息, 当有新事务启动时, 为每一个事务分配 trx_t, 并且在 REPEATABLE READ 隔离级别下, 在事务开启时就需要分配一个 Read View, 用来约束该事务内所有查询的 Record 的可见性(通过 m_low_limit_id 和 m_up_limit_id), 事务内的每一次查询都需要与该 Read View 比较可见性.
trx_no 的作用
trx_no 在每次事务 commit 阶段申请, 在 purge 阶段使用 oldest read-view 的 trx_no 来和 undo log 里记录的 trx_no 比较判断是否可以被安全的 purge.
所以假如在 RC 隔离级别(事务的每条 SQL单独申请一个 read-view), 没有 trx_no, 单纯依赖 trx_id, 我们该如何进行 undo purge ?
为了能安全的进行 purge, 我们需要保证当前的 undo log 不会被当前所有的活跃事务再读取, 我们可以使用下列方法:
- 保证当前 undo log 里记录的 trx_id 小于 oldest read-view 记录的最小 trx_id 或者不存在该 read-view 的活跃事务列表中.
这就保证了持有 oldest read-view 的事务不会再使用该 undo log, 但是 purge_sys 的 queue 里的 undo log 却没有提交序列,我们需要遍历所有的回滚段才能判断哪些 undo log 可以被 purge.
为此引入 trx_no, trx_no 的体现了事务的 commit 顺序.
read-view 的 trx_no 在每次申请 read-view 是从 serialisation_list 里获取, 这里的 trx_no 代表的是当时事务列表里尚未开启的最大的 trx_id, 后面所有开启的事务 trx_id 都会大于这个 trx_no, 所以后面开启事务的 read-view 不会在活跃事务列表中包括小于这个 trx_no 的事务 id.
serialisation_list 是当前进入 commit 阶段的事务的提交顺序列表, 在这里获取所有提交中事务最小的 trx_no, 在 undo log purge 阶段, 如果这个 read-view 是 oldest read-view, 那么小于 m_low_limit_no 的 undo log 都可以进行 purge. 所有小于该 trx_no 的事务都不需要被其他活跃事务读取, 所以可以安全的被 purge.
总结
结合上一篇InnoDB的事务分析-Undo Log我们能大致的梳理 MySQL 的事务的启动流程和事务流程, 通过 MVCC 数据库能保证事务的隔离级别并且避免了开销更大的行级锁.