准备
内核版本: 5.0
Page Cache 是内核与存储介质的重要缓存结构,当我们使用 write() 或者 read() 读写文件时,假如不使用 O_DIRECT 标志位打开文件,我们均需要经过 Page Cache 来帮助我们提高文件读写速度。而在 MySQL 的设计实现中,读写数据文件使用了 O_DIRECT 标志,其目的是使用自身 Buffer Pool 的缓存算法。
根据之前总结的 Linux 内存管理文章,在 Linux 内核内存的基本单元是 Page,而 Page Cache 也驻存于物理内存,所以 Page Cache 的缓存基本单位也是 Page,而 Page Cache 缓存的内容属于文件系统,所以 Page Cache 属于文件系统与物理内存管理的枢纽。
介绍 Page Cache 必不可少的需要涉及VFS的内容,这里我们仅仅简单的介绍相关数据结构的具体含义,文件系统的实现细节暂且略过。Page Cache 整个模块代码量巨大,我们侧重于 Page Cache 的刷脏策略分析。
Page Cache
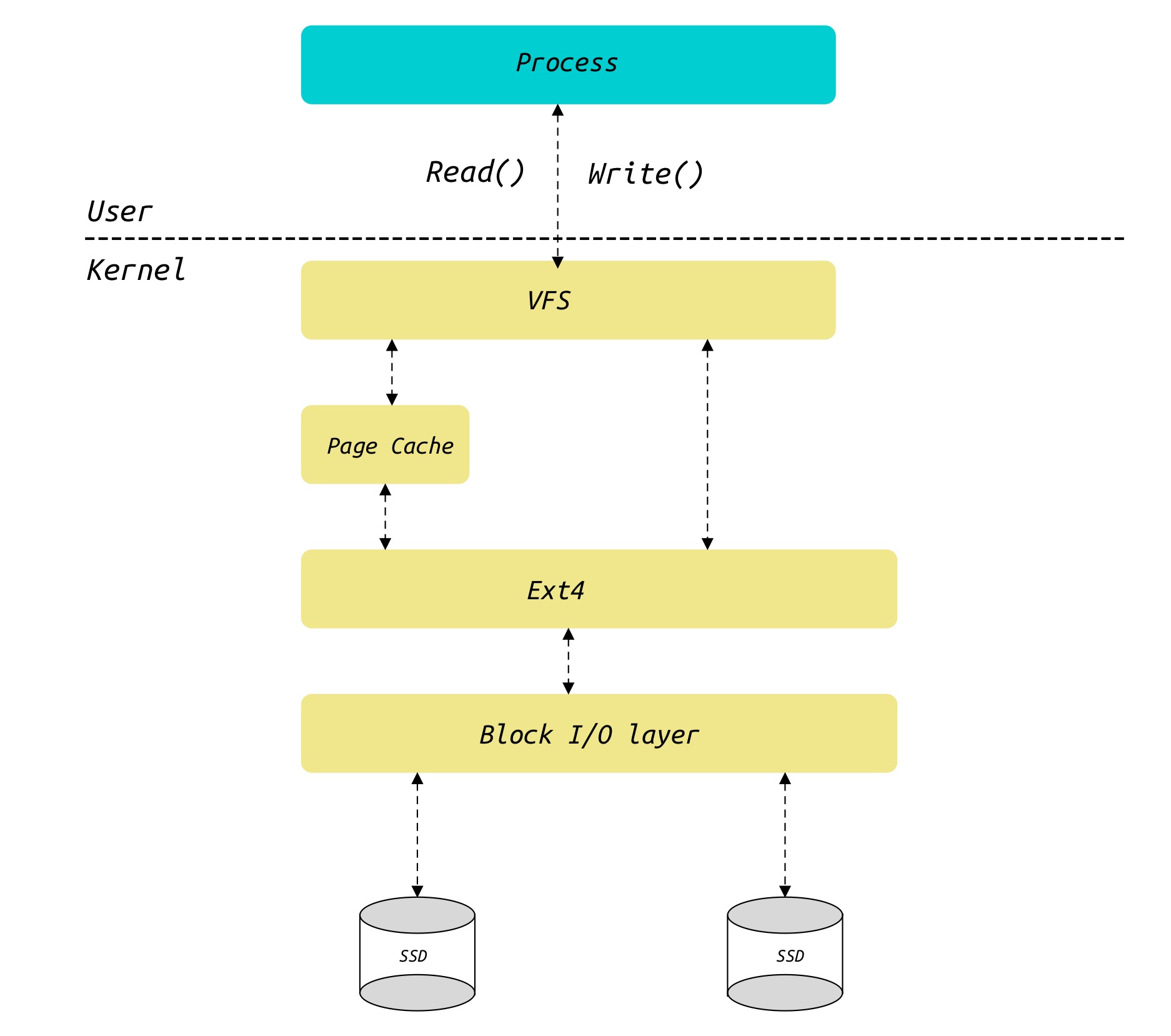
Page Cache 相关数据结构
inode
include/linux/fs.h
inode 在文件系统代表一个文件的元信息结构。
struct inode {
/* ... */
struct address_space i_mapping;
/* ... */i_mapping代表inode所拥有的address_space
address_space
include/linux/fs.h
这里我们假定 address_space 缓存的 Page 来自于磁盘上的文件,而 Page Cache 并不是类似于 MySQL 中 Buffer Pool 一个缓存结构,它结合了于内核的内存管理和文件系统的 address_space 结构。address_space 管理对应的文件映射在物理内存中缓存 Page:
struct address_space {
struct inode *host;
struct xarray i_pages;
gfp_t gfp_mask;
atomic_t i_mmap_writable;
struct rb_root_cached i_mmap;
struct rw_semaphore i_mmap_rwsem;
unsigned long nrpages;
unsigned long nrexceptional;
pgoff_t writeback_index;
const struct address_space_operations *a_ops;
unsigned long flags;
errseq_t wb_err;
spinlock_t private_lock;
struct list_head private_list;
void *private_data;
} __attribute__((aligned(sizeof(long)))) __randomize_layout;-
host代表address_space所属的inode。 -
i_pages代表该address_space缓存的Page。 -
gfp_mask代表内存分配flags。 -
i_mmap_writable代表共享内存映射的Page数量。 -
i_mmap代表该address_space缓存的Page所存放的rb-tree。 -
i_mmap_rwsem用来保护i_mmap和i_mmap_writable的自旋锁。 -
nrpages代表该address_space缓存的Page数量。 -
writeback_index代表回写时所使用的索引。 -
a_ops代表address_space的操作方法函数。 -
flags代表错误位。 -
wb_err代表address_space最近操作方式的错误码。 -
private_lock用来保护private_list的自旋锁。
address_space_operations
address_space_operations 代表 address_space 支持的操作方法:
struct address_space_operations {
int (*writepage)(struct page *page, struct writeback_control *wbc);
int (*readpage)(struct file *, struct page *);
/* Write back some dirty pages from this mapping. */
int (*writepages)(struct address_space *, struct writeback_control *);
/* Set a page dirty. Return true if this dirtied it */
int (*set_page_dirty)(struct page *page);
/*
* Reads in the requested pages. Unlike ->readpage(), this is
* PURELY used for read-ahead!.
*/
int (*readpages)(struct file *filp, struct address_space *mapping,
struct list_head *pages, unsigned nr_pages);
int (*write_begin)(struct file *, struct address_space *mapping,
loff_t pos, unsigned len, unsigned flags,
struct page **pagep, void **fsdata);
int (*write_end)(struct file *, struct address_space *mapping,
loff_t pos, unsigned len, unsigned copied,
struct page *page, void *fsdata);
/* Unfortunately this kludge is needed for FIBMAP. Don't use it */
sector_t (*bmap)(struct address_space *, sector_t);
void (*invalidatepage) (struct page *, unsigned int, unsigned int);
int (*releasepage) (struct page *, gfp_t);
void (*freepage)(struct page *);
ssize_t (*direct_IO)(struct kiocb *, struct iov_iter *iter);
/*
* migrate the contents of a page to the specified target. If
* migrate_mode is MIGRATE_ASYNC, it must not block.
*/
int (*migratepage) (struct address_space *,
struct page *, struct page *, enum migrate_mode);
bool (*isolate_page)(struct page *, isolate_mode_t);
void (*putback_page)(struct page *);
int (*launder_page) (struct page *);
int (*is_partially_uptodate) (struct page *, unsigned long,
unsigned long);
void (*is_dirty_writeback) (struct page *, bool *, bool *);
int (*error_remove_page)(struct address_space *, struct page *);
/* swapfile support */
int (*swap_activate)(struct swap_info_struct *sis, struct file *file,
sector_t *span);
void (*swap_deactivate)(struct file *file);
};writepage:将Page写回磁盘。readpage: 从磁盘读取Page。writepages: 写多个Page至磁盘。set_page_dirty:设置某个Page为脏页。readpages: 读取多个Page, 一般用来预读。write_begin: 准备一个写操作。write_end: 完成一个写操作。invalidatepage:使该Page无效。releasepage:释放Page。direct_IO:对address_space中的所有Page进行DIO。
Page Cache 的插入
我们在Linux内核源码分析-内存请页机制中分析了缺页中断时,当访问的 Page Table 尚未分配,即 vma 对应磁盘上的某一个文件时,会调用 vma->vm_ops->fault(vmf) 对应的文件系统的缺页处理函数。
基本流程
page = page_cache_alloc();
/* ... */
__add_to_page_cache(page, mapping, index, hash);以 ext4 为例,ext4_filemap_fault() 为缺页处理函数,具体调用了内存管理模块的 filemap_fault() 来完成:
vm_fault_t filemap_fault(struct vm_fault *vmf)
{
/* 查找缺页是否存在于 Page Cache.
mapping 为该文件的 adress_space,
offset 为该页的偏移量.
*/
page = find_get_page(mapping, offset);
if (likely(page) && !(vmf->flags & FAULT_FLAG_TRIED)) {
/* 假如存在,进行预读 */
do_async_mmap_readahead(vmf->vma, ra, file, page, offset);
} else if (!page) {
/* 假如不存在,则进行预读,之后立即尝试 Page Cache 查找,
假如仍然不存在,则跳转 no_cached_page.
*/
do_sync_mmap_readahead(vmf->vma, ra, file, offset);
count_vm_event(PGMAJFAULT);
count_memcg_event_mm(vmf->vma->vm_mm, PGMAJFAULT);
ret = VM_FAULT_MAJOR;
retry_find:
page = find_get_page(mapping, offset);
if (!page)
goto no_cached_page;
}
/* ... */
vmf->page = page;
return ret | VM_FAULT_LOCKED;
no_cached_page:
/* 1. 申请分配一个 Page
2. 将该 Page 添加至Page Cache
3. 调用 address_space 的 readpage() 函数完成该 Page 内容的读取
*/
error = page_cache_read(file, offset, vmf->gfp_mask);
/* ... */
}
EXPORT_SYMBOL(filemap_fault);Page Cache 的插入主要流程如下:
- 判断查找的 Page 是否存在于 Page Cache,存在即直接返回
- 否则通过[ Linux 内核物理内存分配](http://leviathan.vip/2019/04/13/Linux%E5%86%85%E6%A0%B8%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90-%E7%89%A9%E7%90%86%E5%86%85%E5%AD%98%E7%9A%84%E5%88%86%E9%85%8D/#%E6%A0%B8%E5%BF%83%E7%AE%97%E6%B3%95介绍的伙伴系统分配一个空闲的 Page.
- 将 Page 插入 Page Cache,即插入
address_space的i_pages. - 调用
address_space的readpage()来读取指定 offset 的 Page.
Page Cache 的回写
假如 Page Cache 中的 Page 经过了修改,它的 flags 会被置为 PG_dirty. 在 Linux 内核中,假如没有打开 O_DIRECT 标志,写操作实际上会被延迟刷盘,以下几种策略可以将脏页刷盘:
- 手动调用
fsync()或者sync强制落盘 - 脏页占用比率过高,超过了设定的阈值,导致内存空间不足,触发刷盘(强制回写).
- 脏页驻留时间过长,触发刷盘(周期回写).
在这里我们仅仅分析周期回写和强制回写
bdi
bdi 是 backing device info 的缩写,它描述备用存储设备相关信息,就是我们通常所说的存储介质 SSD 硬盘等等。Linux 内核为每一个存储设备构造了一个 backing_dev_info,假如磁盘有几个分区,每个分区对应一个 backing_dev_info 结构体.
backing_dev_info
/* include/linux/backing-dev-defs.h */
struct backing_dev_info {
struct list_head bdi_list;
...
struct bdi_writeback wb; /* the root writeback info for this bdi */
...
}bdi_list是全局维护的所有backing_dev_info链表.wb是脏页回写控制块.
bdi_writeback
/* include/linux/backing-dev-defs.h */
struct bdi_writeback {
struct backing_dev_info *bdi; /* our parent bdi */
...
struct list_head b_dirty; /* dirty inodes */
struct list_head b_io; /* parked for writeback */
...
struct delayed_work dwork; /* work item used for writeback */
}-
bdi是该bdi_writeback所属的backing_dev_info. -
b_dirty代表文件系统中被修改的inode节点. -
b_io代表等待 I/O 的inode节点. -
dwork是一个封装的延迟工作任务,由它的主函数将脏页回写存储设备:/* mm/backing-dev.c */ /* wb_init() 用来初始化 backing_dev_info */ static int wb_init(struct bdi_writeback *wb, struct backing_dev_info *bdi, int blkcg_id, gfp_t gfp) { ... INIT_LIST_HEAD(&wb->b_dirty); INIT_LIST_HEAD(&wb->b_io); INIT_LIST_HEAD(&wb->b_more_io); INIT_LIST_HEAD(&wb->b_dirty_time); spin_lock_init(&wb->list_lock); wb->bw_time_stamp = jiffies; wb->balanced_dirty_ratelimit = INIT_BW; wb->dirty_ratelimit = INIT_BW; wb->write_bandwidth = INIT_BW; wb->avg_write_bandwidth = INIT_BW; spin_lock_init(&wb->work_lock); INIT_LIST_HEAD(&wb->work_list); /* dwork的回调函数为wb_workfn() */ INIT_DELAYED_WORK(&wb->dwork, wb_workfn); ... }
bdi_writeback 对象封装了 dwork 以及需要处理的 inode 队列。当 Page Cache 调用 __mark_inode_dirty() 时,将需要刷脏的 inode 挂载到 bdi_writeback 对象的 b_dirty 队列上,然后唤醒对应的 bdi 刷脏线程。
wb_workfn()
wb_workfn 是回写控制块的回调函数
/* fs/fs-writeback.c */
void wb_workfn(struct work_struct *work)
{
...
if (likely(!current_is_workqueue_rescuer() ||
!test_bit(WB_registered, &wb->state))) {
/*
* 调用 wb_do_writeback() 完成回写操作
*/
do {
pages_written = wb_do_writeback(wb);
trace_writeback_pages_written(pages_written);
} while (!list_empty(&wb->work_list));
} else {
...
}
...
}wb_do_writeback 分别实现了周期回写和后台回写两部分: wb_check_old_data_flush(),wb_check_background_flush(),具体实现我们分不同的场景分析,因为每一个存储设备都有一个 backing_dev_info,所以每个存储设备之间的脏页回写互不影响.
周期回写
周期回写的时间单位是0.01s,默认为5s,可以通过 /proc/sys/vm/dirty_writeback_centisecs 调节:
/* mm/page-writeback.c */
/*
* The interval between `kupdate'-style writebacks
*/
unsigned int dirty_writeback_interval = 5 * 100; /* centiseconds */Page 驻留为 dirty 状态的时间单位也为0.01s,默认为30s,可以通过 /proc/sys/vm/dirty_expire_centisecs 来调节:
/* mm/page-writeback.c */
/*
* The longest time for which data is allowed to remain dirty
*/
unsigned int dirty_expire_interval = 30 * 100; /* centiseconds */后台线程周期回写
/* fs/fs-writeback.c */
static long wb_check_old_data_flush(struct bdi_writeback *wb)
{
unsigned long expired;
long nr_pages;
/* 假如没有设置 dirty_writeback_interval, 直接返回 */
if (!dirty_writeback_interval)
return 0;
/* 将 dirty_writeback_interval 转换为 jiffies 再加上上一次刷脏的 jiffies 大小, jiffies 是 Linux 内核定义的时间单位 HZ. */
expired = wb->last_old_flush +
msecs_to_jiffies(dirty_writeback_interval * 10);
/* 假如还没有超时,直接返回 */
if (time_before(jiffies, expired))
return 0;
wb->last_old_flush = jiffies;
/* 获取 dirty 状态的 inode */
nr_pages = get_nr_dirty_pages();
if (nr_pages) {
struct wb_writeback_work work = {
.nr_pages = nr_pages,
.sync_mode = WB_SYNC_NONE,
.for_kupdate = 1,
.range_cyclic = 1,
.reason = WB_REASON_PERIODIC,
};
/* 假如存在被修改过的inode节点,调用wb_writeback() */
return wb_writeback(wb, &work);
}
return 0;
}强制回写
强制回写分为后台线程回写和用户进程主动回写。
当脏页数量超过了设定的阈值,后台回写线程会将脏页写回存储设备,后台回写阈值是脏页占可用内存大小的比例或者脏页的字节数,默认比例是10. 用户可以通过修改 /proc/sys/vm/dirty_background_ratio 修改脏页比或者修改 /proc/sys/vm/dirty_background_bytes 修改脏页的字节数。
而在用户调用 write() 接口写文件时,假如脏页占可用内存大小的比例或者脏页的字节数超过了设定的阈值,会进行主动回写,用户可以通过设置 /proc/sys/vm/dirty_ratio 或者 /proc/sys/vm/dirty_bytes 修改这两个阈值。
后台线程强制回写
/* fs/fs-writeback.c */
static long wb_check_background_flush(struct bdi_writeback *wb)
{
/* wb_over_bg_thresh()检查脏页的数量是否超过了设定的阈值 */
if (wb_over_bg_thresh(wb)) {
struct wb_writeback_work work = {
.nr_pages = LONG_MAX,
.sync_mode = WB_SYNC_NONE,
.for_background = 1,
.range_cyclic = 1,
.reason = WB_REASON_BACKGROUND,
};
/* 假如超过了阈值,调用wb_writeback() */
return wb_writeback(wb, &work);
}
return 0;
}用户进程触发回写
假如用户调用 write() 或者其他写文件接口时,在写文件的过程中,产生了脏页后会调用 balance_dirty_pages 调节平衡脏页的状态. 假如脏页的数量超过了**(后台回写设定的阈值+ 进程主动回写设定的阈值) / 2 **,即 (background_thresh + dirty_thresh) / 2 会强制进行脏页回写. 用户线程进行的强制回写仍然是触发后台线程进行回写
总结
触发 Page Cache 刷脏的几个条件如下:
- 周期回写,可以通过设置
/proc/sys/vm/dirty_writeback_centisecs调节周期. - 当后台回写阈值是脏页占可用内存大小的比例或者脏页的字节数超过了设定的阈值会触发后台线程回写.
- 当用户进程写文件时会进行脏页检查假如超过了阈值会触发回写,从而调用后台线程完成回写.
Page 的写回操作是文件系统的封装,即 address_space 的 writepage 操作.
思考
因为Linux内核为每个存储设备都设置了刷脏进程,所以假如在日常开发过程遇到了刷脏压力过大的情况下,在条件允许的情况下,将写入文件分散在不同的存储设备,可以提高的写入速度,减小刷脏的压力.