MySQL 二级索引分析
前言
在 MySQL 中,创建一张表时会默认为主键创建聚簇索引,B+ 树将表中所有的数据组织起来,即数据就是索引主键所以在 InnoDB 里,主键索引也被称为聚簇索引,索引的叶子节点存的是整行数据。而除了聚簇索引以外的所有索引都称为二级索引,二级索引的叶子节点内容是主键的值。
二级索引
创建二级索引
CREATE INDEX [index name] ON [table name]([column name]);或者
ALTER TABLE [table name] ADD INDEX [index name]([column name]);在 MySQL 中, CREATE INDEX 操作被映射为 ALTER TABLE ADD_INDEX。
二级索引格式
例如创建如下一张表:
CREATE TABLE users(
id INT NOT NULL,
name VARCHAR(20) NOT NULL,
age INT NOT NULL,
PRIMARY KEY(id)
);新建一个以 age 字段的二级索引:
ALTER TABLE users ADD INDEX index_age(age);MySQL 会分别创建主键 id 的聚簇索引和 age 的二级索引:
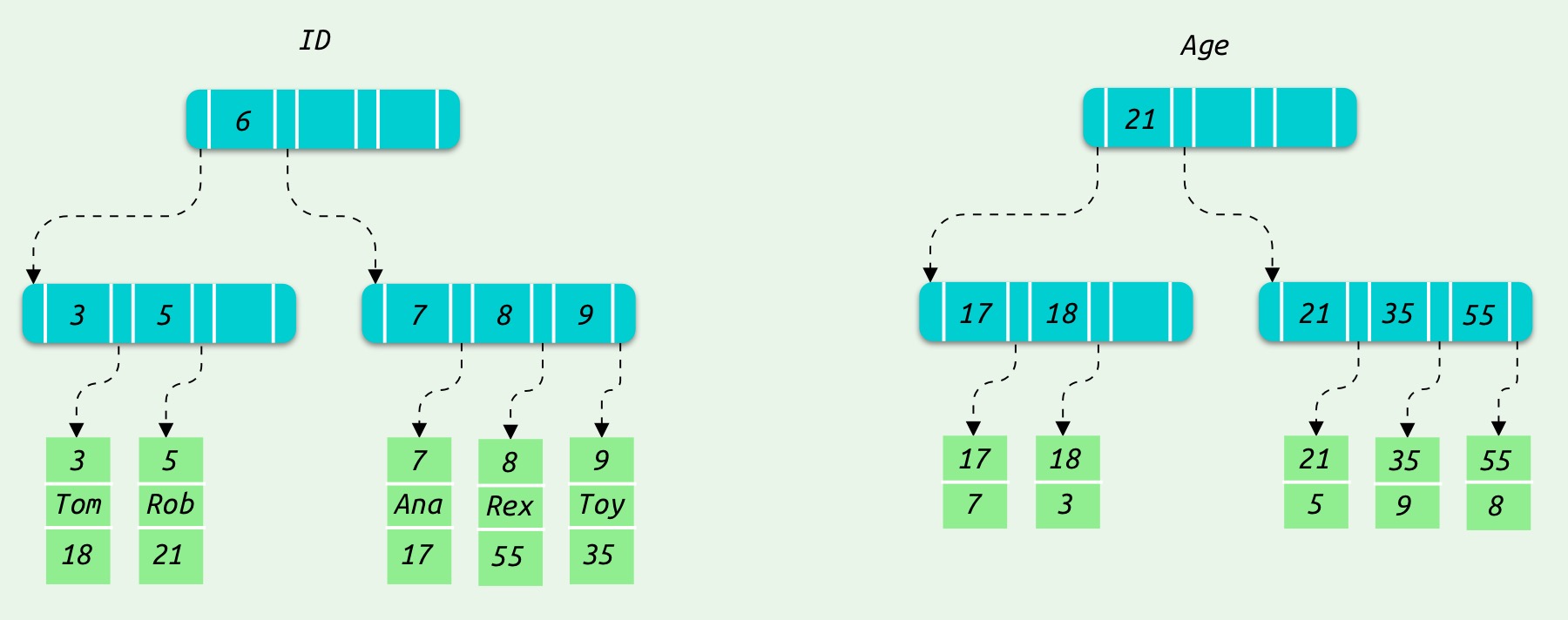
在 MySQL 中主键索引的叶子节点存的是整行数据,而二级索引叶子节点内容是主键的值.
二级索引的创建流程
在 MySQL 8.0 中,二级索引的创建具体流程如下图:
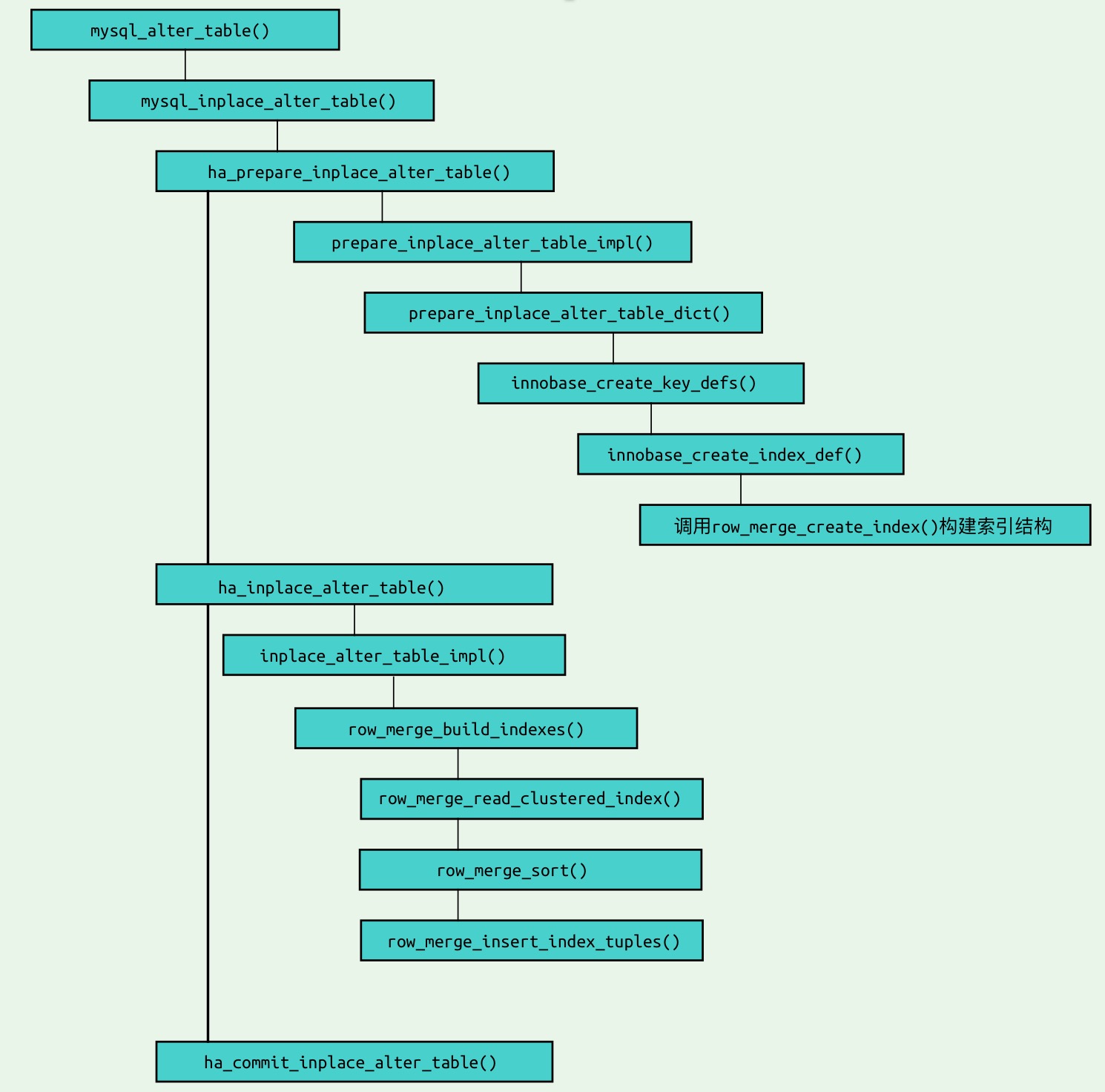
二级索引所属的 Onine DDL 可以分为三个阶段: DDL prepare 阶段, DDL 执行阶段和 DDL commit 阶段.
DDL prepare 阶段
-
升级至 X 锁, 禁止读写.
-
ha_prepare_inplace_alter_table()根据ALTER TABLE语句传入的参数进行检查,构建被创建的索引信息,创建索引的B+树.
DDL 执行阶段
在 MySQL 8.0 实现中,基本上所有的 ALTER TABLE 操作都实现在 mysql_alter_table() 函数,而 Online DDL 支持使用 Inplace 方式创建二级索引:
-
row_merge_build_indexes()用来构建二级索引的索引内容,在 MySQL 中,二级索引的组织关系是 <Key, Primay key> 即指定的索引 column 与主键组成的映射关系. 所以需要读取聚簇索引来构建二级索引内容:-
申请内存用来排序,大小为
3 * srv_sort_buf_size,申请临时文件merge_file_t用来合并排序. -
读取扫描表中的整个聚簇索引 B+ 树构建二级索引,假如
merge buffer的空间不满足 Index 的排序,则需要利用临时文件进行合并排序. -
根据
prepare阶段构建的索引信息,遍历聚簇索引,构造对应的索引字段. 假如建表时没有指定主键,InnoDB 会默认创建一个名为DB_ROW_ID的自增字段,所以二级索引的映射关系就是<Key, DB_ROW_ID>. -
将合并排序后的二级索引内容通过 Bulk Load 的方式写入Page,使用
flush_observer落盘对应的数据脏页. -
关闭删除临时文件,释放排序内存
merge_buf.
-
MySQL 8.0 要求 DDL 具有原子性,所以在上述的合并排序后插入 Page 的过程中,可以使用 flush_observer 直接落盘数据页或者记录 Redo. 这样来保证整个DDL操作是原子的.
DDL commit 阶段
-
为 Table 加上 X 锁, 禁止读写.
-
更新 InnoDB 的数据字典 DD.
-
提交 DDL 事务.
-
清理操作 Clean Up.
在一些需要 rebuild table 的 Online DDL 操作中,例如 Dropping a column, 为了不阻塞 DML 操作,需要引入 row_log 来暂存在 DDL 过程中用户的数据修改操作,而在二级索引的创建过程中并不需要 rebuild table, 所以不需要 row_log_table, 用户对于其他字段的数据的修改可以直接基于聚簇索引进行修改, 而对于创建二级索引的字段,需要通过 row_log 来处理二级索引创建过程中的 DML 操作.
假如二级索引创建的过程中发生 Crash, 重启后打开临时文件的 Tablespace 会清理上次意外 Crash 遗留的临时文件.
索引定义
/** Definition of an index being created */
struct index_def_t {
const char *name; /*!< index name */
bool rebuild; /*!< whether the table is rebuilt */
ulint ind_type; /*!< 0, DICT_UNIQUE,
or DICT_CLUSTERED */
ulint key_number; /*!< MySQL key number,
or ULINT_UNDEFINED if none */
ulint n_fields; /*!< number of fields in index */
index_field_t *fields; /*!< field definitions */
/* ... */
};name即索引名.rebuild表示是否需要重建表.ind_type表示索引类型.key_number表示表中索引数量.n_fields表示索引字段的数量.fields表示索引字段的定义.
二级索引的检索过程
在 MySQL 的查询过程中,SQL 优化器会选择合适的索引进行检索,在使用二级索引的过程中,因为二级索引没有存储全部的数据,假如二级索引满足查询需求,则直接返回,即为覆盖索引,反之则需要回表 (Row_sel_get_clust_rec_for_mysql) 去主键索引(聚簇索引)查询。
例如执行 SELECT * FROM users WHERE age=35; 则需要进行回表:
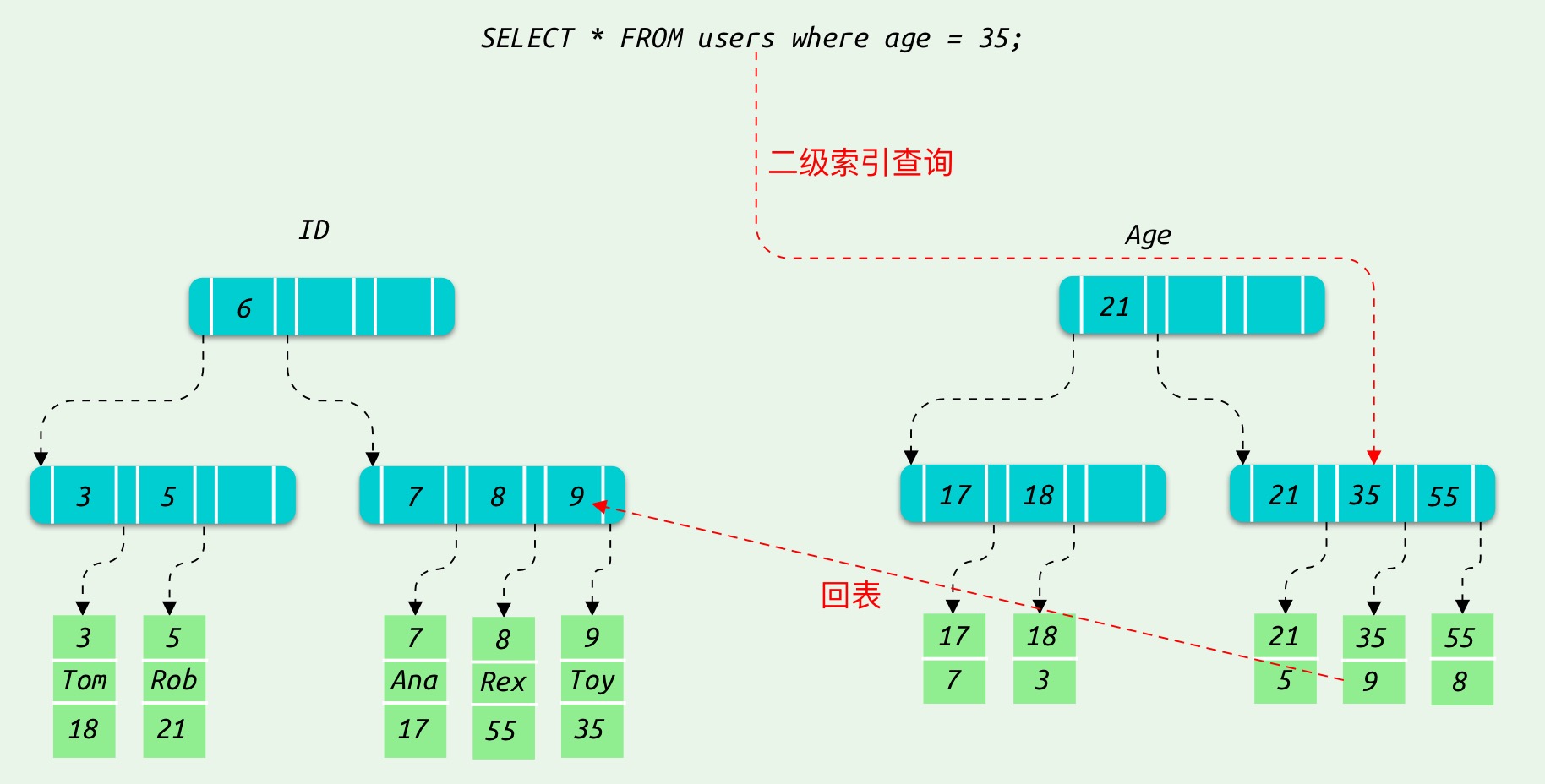
使用 EXPLAIN 查看执行计划可以看到使用的索引是我们之前创建的 index_age:
MySQL [sbtest]> EXPLAIN SELECT * FROM users WHERE age=35;
+----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | users | NULL | ref | index_age | index_age | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)总结
二级索引是指定字段与主键的映射,主键长度越小,普通索引的叶子节点就越小,二级索引占用的空间也就越小,所以要避免使用过长的字段作为主键。