版本
- 1.4.0 “Andium”
引言
在文章 DuckDB 查询执行器架构解析 和 DuckDB 源码分析 - Logical Plan 逻辑计划 中, 我们梳理了 DuckDB 的查询执行流程和逻辑计划生成. 基表扫描在物理层统一为 PhysicalTableScan (顺序扫与索引扫都是如此); 当优化器选用 ART 时, 仍在该算子上走 Index Scan 路径 (表扫描初始化阶段先经 ART 得到 row_id 再取行), EXPLAIN 中会显示为 Index Scan, 而非单独的 PhysicalIndexScan 算子.
ART (Adaptive Radix Tree) 索引是 DuckDB 中用于加速高选择性查询和确保主键约束的核心数据结构.
MySQL 的存储引擎 InnoDB 是行存引擎, 使用的是 B+tree 索引结构, 索引即数据, 磁盘上的数据文件可以理解为 B+tree 索引结构的直接映射. DuckDB 的 ART 是分离式索引, 具有普遍的索引意义, ART 索引只存 row_id. 如果需要获取整行数据, 查询语句需要通过 ART 获取 row_id, 再通过 RowGroup 在列式的数据文件中查找具体的数据行.
列存场景里另一类常见加速是 按块/行组的统计信息 (如 min-max、zonemap) 在表扫描时整块跳过; ART 则是 精确到 row_id 的辅助结构, 更适合高选择性点查、范围与主键/唯一约束。二者互补, 本文只讨论 ART.
关于 ART 索引的理论基础, 可以参考原始论文:
DuckDB 的官方也有关于 ART 索引的博客介绍:
下文侧重整体结构与关键路径, 细节请对照版本源码与调试自行展开.
ART 索引
Adaptive Radix Tree
ART (Adaptive Radix Tree) 是一种内存高效的基数树 (Radix Tree) 变体, 由 Leis et al. 在 2013 年提出. 与传统的基数树不同, ART 通过自适应节点大小来减少内存浪费, 同时保持 O(k) 的查找复杂度 (k 为键的长度).
ART 索引创建时机
CREATE INDEX 语句解析
当用户执行 CREATE INDEX 语句时, DuckDB 会经历以下流程来创建 ART 索引:
- SQL 解析:
Transformer::TransformCreateIndex(见transform_create_index.cpp) 解析 CREATE INDEX 语句, 生成CreateIndexInfo - 绑定阶段:
IndexBinder::BindCreateIndex绑定索引定义, 验证表名和列名; catalog 侧由DuckCatalog::BindCreateIndex等接入 - 逻辑计划: 生成
LogicalCreateIndex节点 - 物理计划: 转换为
PhysicalCreateIndex算子
PRIMARY KEY 和 UNIQUE 约束的自动创建
DuckDB 会在创建表时自动为 PRIMARY KEY 和 UNIQUE 约束创建 ART 索引. 这个过程发生在约束绑定阶段:
- 约束定义:
CREATE TABLE中的 PRIMARY KEY/UNIQUE 约束在Binder::BindCreateTable中被识别 - 约束绑定:
Binder::BindConstraint处理约束, 创建BoundUniqueConstraint - 索引创建: 在
DuckTableEntry构造表存储DataTable时, 对 UNIQUE/PRIMARY KEY 等约束调用DataTable::AddIndex创建对应的 ART 索引 (与约束绑定结果对应, 而非单独的TableStorage::CreateIndexes之类入口)
查询语句中的索引使用
当执行查询语句时, DuckDB 的查询优化器会评估是否可以使用已有的 ART 索引来加速查询:
- 索引选择: 优化器在生成物理计划时, 会检查查询条件是否匹配已有的索引 (如等值查询, 范围查询等)
- 索引扫描: 若优化器选用索引, 仍为
PhysicalTableScan配合 Index Scan 路径: 利用 ART 快速得到row_id, 再通过 RowGroup 获取完整行数据 (EXPLAIN中为 Index Scan)
需要注意的是, DuckDB 不会在执行普通查询语句时自动创建新索引. 索引的创建需要通过显式的 CREATE INDEX 语句, 或者在表定义时通过 PRIMARY KEY/UNIQUE 约束自动创建. 在执行 CREATE INDEX 语句时, DuckDB 会通过 PhysicalCreateIndex 算子扫描表数据并调用 ART::Build 方法构建 ART 索引结构.
是否走 Index Scan 还取决于选择性、可用索引定义与代价估计; 当前实现里对「索引扫描」的尝试主要针对单列 ART (复合/多列 ART 的 index scan 在表扫描初始化路径上尚未按传统「最左前缀」那套接好), 勿直接套用 InnoDB 复合索引经验. 排障时可用 EXPLAIN / EXPLAIN ANALYZE 对照计划是否走索引。代价模型与规则细节可单独成篇展开.
ART 索引结构
class ART : public BoundIndex {
public:
friend class Leaf;
public:
/* ... */
public:
/* 扫描/查找. */
bool Scan(IndexScanState &state, idx_t max_count, set<row_t> &row_ids);
/* 追加写. */
ErrorData Append(IndexLock &l, DataChunk &chunk, Vector &row_ids) override;
/* 插入写. */
ErrorData Insert(IndexLock &l, DataChunk &chunk, Vector &row_ids) override;
/* 删除. */
void Delete(IndexLock &lock, DataChunk &entries, Vector &row_ids) override;
/* 构建 ART 索引. */
ARTConflictType Build(unsafe_vector<ARTKey> &keys, unsafe_vector<ARTKey> &row_ids, const idx_t row_count);
/* 将 ART 索引持久化到磁盘. */
IndexStorageInfo SerializeToDisk(QueryContext context, const case_insensitive_map_t<Value> &options) override;
/* ... */
private:
/* ... */
};SerializeToDisk 负责把内存中的 ART 落盘; 与 checkpoint、重启后加载、以及 WAL 在崩溃恢复中的职责划分, 官方 Persistent Storage of Adaptive Radix Trees (ART) in DuckDB 有系统说明, 本文不展开具体文件布局.
节点类型
在传统的 Radix 索引树中, 如果每一层都固定用 256 槽位 (Node256) 来表示"一个字节的分支", 那么在分支很稀疏时会产生大量空位, 浪费内存并降低 cache 命中率. ART 的思路是: 同一层节点根据"当前分支数"自适应选择不同布局.
DuckDB 的 ART 实现了完整的自适应基数树节点体系, 并且有所扩展, 下表列出了所有节点类型及其含义:
DuckDB 的 ART 里最核心的四类 “自适应分支节点” 是:
- Node4: 分支数很少时使用.
- Node16: 分支数变多后扩容到 16.
- Node48: 用一个 256 大小的索引表把 byte 映射到 0..47 的紧凑 child 数组.
- Node256: 直接 256 槽位数组, 按 byte O(1) 访问.
DuckDB 针对 ART 的节点类型做了扩展, 专门设置了 prefix 节点和存储 row_id 的节点.
/* src/include/duckdb/execution/index/art/node.hpp */
/* 节点类型. */
enum class NType : uint8_t {
PREFIX = 1,
LEAF = 2,
NODE_4 = 3,
NODE_16 = 4,
NODE_48 = 5,
NODE_256 = 6,
LEAF_INLINED = 7,
NODE_7_LEAF = 8,
NODE_15_LEAF = 9,
NODE_256_LEAF = 10,
};LEAF_INLINED 用来存储完整的 row_id.
NODE_[X]_LEAF 是作为嵌套 ART 节点, 用于存储 row_id 的最后一个字节值. 在嵌套 ART 中, row_id 的前面字节通过 PREFIX 节点或分支节点存储, 最后一个字节存储在 NODE_X_LEAF 中 (X 表示容量: 7, 15 或 256), 以此来节省空间.
| 节点类型 | 枚举值 | 具体含义 |
|---|---|---|
| PREFIX | NType::PREFIX = 1 |
路径压缩节点, 存储连续单分支路径的公共前缀字节, 减少树高和内存占用 |
| LEAF | NType::LEAF = 2 |
已弃用 |
| NODE_4 | NType::NODE_4 = 3 |
分支数为 4 的节点 |
| NODE_16 | NType::NODE_16 = 4 |
分支数为 16 的节点 |
| NODE_48 | NType::NODE_48 = 5 |
分支数为 48 的节点 |
| NODE_256 | NType::NODE_256 = 6 |
直接使用 256 槽位数组, 按 byte 值 O(1) 访问, 内存占用最大但查找最快 |
| LEAF_INLINED | NType::LEAF_INLINED = 7 |
内联叶子节点, 将单个 row_id 直接存储在 Node 指针中, 避免额外内存分配 |
| NODE_7_LEAF | NType::NODE_7_LEAF = 8 |
存储最多 7 个排序的字节值 |
| NODE_15_LEAF | NType::NODE_15_LEAF = 9 |
存储最多 15 个排序的字节值 |
| NODE_256_LEAF | NType::NODE_256_LEAF = 10 |
使用掩码的方式存储 row_id 最后一个字节 |
/* 基础节点, Node 4 和 Node16 采用该结构. */
template <uint8_t CAPACITY, NType TYPE>
class BaseNode {
friend class Node4;
friend class Node16;
friend class Node48;
public:
BaseNode() = delete;
BaseNode(const BaseNode &) = delete;
BaseNode &operator=(const BaseNode &) = delete;
private:
uint8_t count;
uint8_t key[CAPACITY];
Node children[CAPACITY];
/* ... */
}
/* Node48 节点结构. */
class Node48 {
friend class Node16;
friend class Node256;
public:
static constexpr NType NODE_48 = NType::NODE_48;
static constexpr uint8_t CAPACITY = 48;
static constexpr uint8_t EMPTY_MARKER = 48;
static constexpr uint8_t SHRINK_THRESHOLD = 12;
/* ... */
private:
uint8_t count;
uint8_t child_index[Node256::CAPACITY];
Node children[CAPACITY];
}
/* Node256 节点结构. */
class Node256 {
friend class Node48;
public:
static constexpr NType NODE_256 = NType::NODE_256;
static constexpr uint16_t CAPACITY = 256;
static constexpr uint8_t SHRINK_THRESHOLD = 36;
public:
Node256() = delete;
Node256(const Node256 &) = delete;
Node256 &operator=(const Node256 &) = delete;
private:
uint16_t count;
Node children[CAPACITY];
/* ... */
}ART 接口代码导读: Insert 与 Scan
这里只展开两个接口:
- 插入:
ART::Insert - 查找:
TryInitializeScan -> Scan -> SearchEqual -> ARTOperator::Lookup
ARTKey: 数据结构与含义
在 ART 里, 索引 key 的最小单位是 ARTKey, 是一段 按 Byte 可比较 的 buffer.
/* src/include/duckdb/execution/index/art/art_key.hpp */
class ARTKey {
public:
idx_t len; /* key 的字节长度. */
data_ptr_t data; /* key 的字节内容. */
};1) Insert: 写入索引 (ART::Insert / ART::Append)
Insert 把输入的数据编码成 ART key, 然后把真正的树操作交给 ARTOperator::Insert; 如果中途发生冲突, 再把已插入的部分回滚掉.
/* src/execution/index/art/art.cpp */
ErrorData ART::Insert(IndexLock &l, DataChunk &chunk, Vector &row_ids, IndexAppendInfo &info) {
D_ASSERT(row_ids.GetType().InternalType() == ROW_TYPE);
auto row_count = chunk.size();
/* 1. 将 Chunk 里面的数据通过 GenerateKeyVectors 转换为 ART key. */
ArenaAllocator arena(BufferAllocator::Get(db));
unsafe_vector<ARTKey> keys(row_count);
unsafe_vector<ARTKey> row_id_keys(row_count);
GenerateKeyVectors(arena, chunk, row_ids, keys, row_id_keys);
auto conflict_type = ARTConflictType::NO_CONFLICT;
optional_idx conflict_idx;
auto was_empty = !tree.HasMetadata();
/* 2. 将 ART key 一次插入 ART tree. */
for (idx_t i = 0; i < row_count; i++) {
if (keys[i].Empty()) {
continue;
}
conflict_type = ARTOperator::Insert(arena, *this, tree, keys[i], 0, row_id_keys[i], GateStatus::GATE_NOT_SET,
DeleteIndexInfo(info.delete_indexes), info.append_mode);
if (conflict_type != ARTConflictType::NO_CONFLICT) {
conflict_idx = i;
break;
}
}
/* 3. 如果遇到了冲突, 需要回滚插入的 ART key. */
if (conflict_type != ARTConflictType::NO_CONFLICT) {
D_ASSERT(conflict_idx.IsValid());
for (idx_t i = 0; i < conflict_idx.GetIndex(); i++) {
if (keys[i].Empty()) {
continue;
}
D_ASSERT(tree.GetGateStatus() == GateStatus::GATE_NOT_SET);
ARTOperator::Delete(*this, tree, keys[i], row_id_keys[i]);
}
}
/* ... */
return ErrorData();
}ART GATE 的使用
ART GATE 用于处理同一个索引 key 对应多个 row_id 的场景 (例如非唯一索引中多个行具有相同的 key 值).
当同一个 key 需要存储多个 row_id 时, DuckDB 会创建一个标记为 GateStatus::GATE_SET 的 GATE 节点, 并在该节点下嵌套一个以 row_id 为 key 的 ART 子树来组织这些 row_id. 查找时, Iterator 会进入嵌套 ART 树遍历所有对应的 row_id.
ART 写入几个关键点:
- 对整数/浮点等标量类型, 会用
Radix::EncodeData<T>编码, 保证字节序比较的顺序与值大小一致. VARCHAR会对\\x00/\\x01做转义并追加\\0结尾, 避免前缀比较/边界处理出现歧义.- 复合索引 (多列 key) 会把每列编码结果
Concat拼接成一个更长的字节串. - row_id 也会编码成
ARTKey, 需要时用GetRowId()反解回row_t. - Node 根据插入/删除操作进行节点扩容/缩容操作, 比如 Node4 <-> Node16.
索引键中的 NULL 如何在字节级编码、IS NULL 与索引对接, 以及复合键各列拼接顺序是否与 Binder 一致, 与 GenerateKeyVectors 同源, 需对照绑定与编码路径单独梳理.
2) Scan 查找: TryInitializeScan / Scan / SearchEqual
DuckDB 里的 ART 查找入口是 TryInitializeScan/Scan:
TryInitializeScan负责把 filter_expr 识别成 “等值 / 下界 / 上界 / between” 等形态, 并返回 scan state.Scan根据 scan state 分发到SearchEqual(等值) 或其它范围查找.SearchEqual内部调用ARTOperator::Lookup找到 leaf, 然后用Iterator把 leaf 下的 row_id 扫出来.
/* src/execution/index/art/art.cpp */
bool ART::SearchEqual(ARTKey &key, idx_t max_count, set<row_t> &row_ids) {
/* 沿着 ART 定位到 leaf 节点. */
auto leaf = ARTOperator::Lookup(*this, tree, key, 0);
if (!leaf) {
return true;
}
/* 使用 Iterator 扫描获取对应的 row_id. */
Iterator it(*this);
it.FindMinimum(*leaf);
ARTKey empty_key = ARTKey();
return it.Scan(empty_key, max_count, row_ids, false);
}3) Delete: 与 Insert 对称的路径
正文侧重 Insert 与 Scan. 删除侧入口为 ART::Delete, 树操作在 ARTOperator::Delete 中完成; 涉及 GATE 与嵌套 row_id 子树时, 与插入时 GateStatus 的演化对称。唯一约束冲突或批量失败时的回滚, 可与上文 Insert 中「冲突则对已插入键逐条 ARTOperator::Delete」对照阅读。若要逐步调试, 可与 Insert 在同一断点层级下成对跟进。
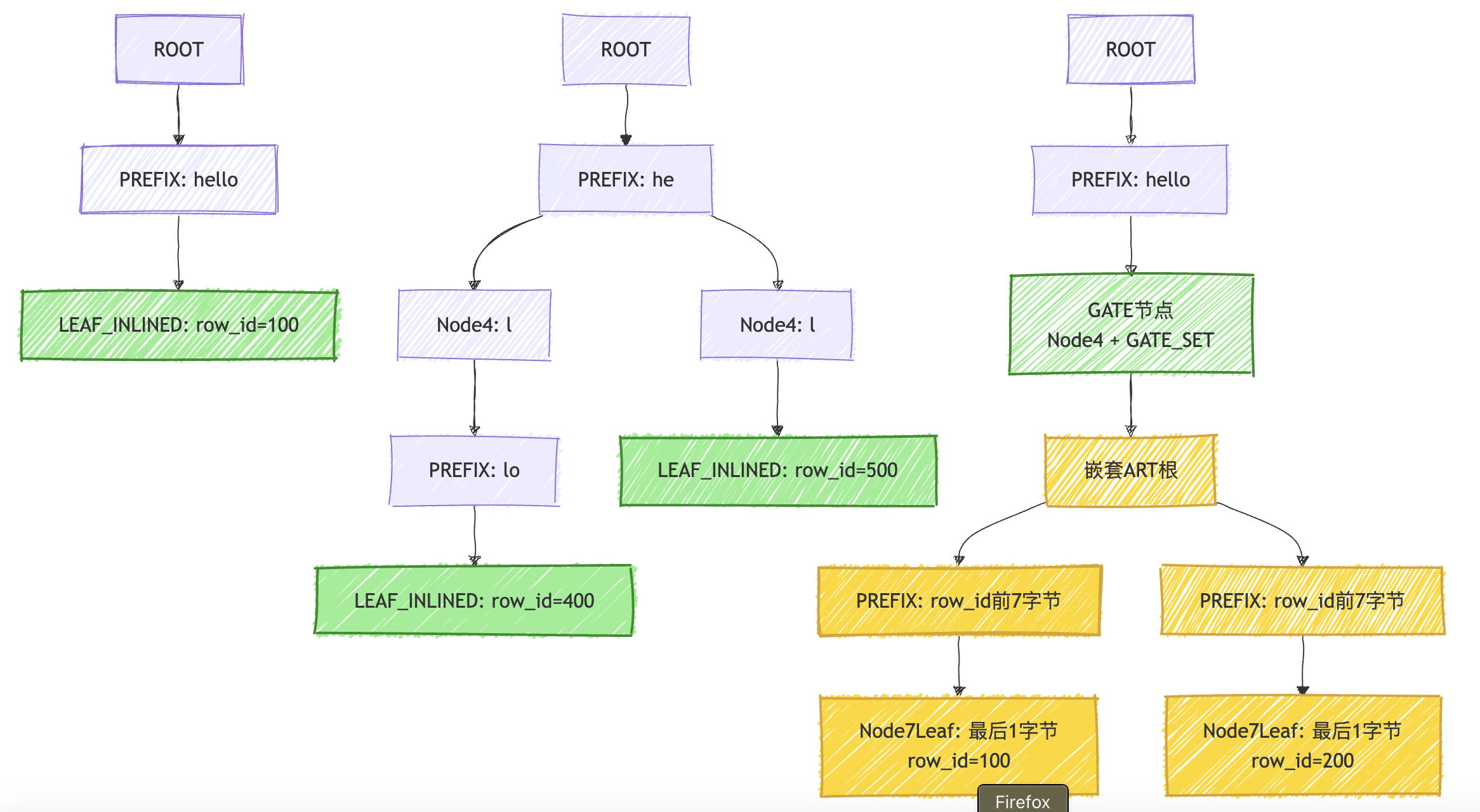
上图展示了 DuckDB ART 索引的三种典型场景:
- 单个 row_id: 当 key 唯一时, 直接通过 PREFIX 节点到达 LEAF_INLINED 节点存储 row_id.
- 多个不同 key: 当多个 key 共享前缀时, 使用 Node4 节点进行分支, 每个分支继续通过 PREFIX 到达各自的叶子节点.
- 相同 key 多个 row_id: 当同一个 key 对应多个 row_id 时, 使用 GATE 节点 (任何节点类型 + GATE_SET 标志) 作为中间层, 然后通过嵌套的 ART 结构来存储多个 row_id. 嵌套 ART 使用完整的 row_id 作为 key, 通过路径压缩, 前面的字节存储在 PREFIX 节点中, 最后一个字节存储在 NODE_X_LEAF 中 (可能是 Node7Leaf, Node15Leaf 或 Node256Leaf, 取决于 row_id 的数量).
DuckDB 的 ART 索引只能检索出 row_id, 需要整行数据需要通过 RowGroup 获取.
ART 索引的并发问题
在 MySQL 8.0 中引入了 SX 锁来支持 B+tree 索引的读写优化, 虽然同时只能进行一个 SMO 操作, 但是读操作可以和写操作同时进行, 这种优化提高了整体读写性能, 对于大量即时读写更新的场景更加友好.
DuckDB 当前的 ART 索引的并发模式采用的是读写完全互斥, 读读操作也需要串行. 这个限制和 DuckDB 的并发访问模式有关 DuckDB Concurrency:
DuckDB has two configurable options for concurrency:
- One process can both read and write to the database.
- Multiple processes can read from the database, but no processes can write (access_mode = ‘READ_ONLY’).
在同一个进程中, 多个线程可以共享一套数据对象, 可以使用 MVCC + 乐观并发在一个进程里协调多个线程的读写操作, 不需要跨进程同步.
在多进程场景里要么都只读,要么在应用层用锁/队列保证 “同一时刻只有一个进程在写”.
而关于 ART 索引的并发问题, 读线程沿 ART 的边往下走,若写线程能同时改节点、分裂、合并,就需要:
- 细粒度锁 / 版本号.
- 读者也串行化 (读读互斥)
DuckDB 在 ART 上选了后者, 整体的实现更加简单, 但是性能会有损耗, DuckDB 在博客里也解释了这个问题:
DuckDB is optimized for bulk operations, so executing many small transactions is not a primary design goal.
DuckDB 面向大批量的 workload, 所以粗粒度的锁模型是可以接受的.
ART 常驻内存, 占用随键分布与节点类型选择而变; 极端倾斜或宽键可能带来节点膨胀, 需结合 workload 观察。索引维护命令与版本差异以官方文档为准, 并与上节多进程只读 / 单进程写模型一并理解。
关于 return std::move()
DuckDB 的 ART 代码中大量使用了 return std::move(), 但其中很多是不必要的, 甚至可能导致性能退化:
C++ RVO/NRVO 机制
C++ 编译器会自动应用两种优化:
- RVO (Return Value Optimization): 对于临时对象, 直接在返回位置构造
- NRVO (Named Return Value Optimization): 对于局部变量, 直接在返回位置构造, 避免拷贝/移动
当返回局部变量时, 编译器会自动应用 NRVO, 不需要 std::move(), 这些局部变量会被编译器自动优化 (NRVO), std::move() 反而可能阻止 NRVO, 强制使用移动构造反而造成性能回退.
总结
通过自适应节点大小, ART index 在内存效率和查找性能之间取得了良好的平衡, 特别适合 AP 列存数据库的场景.
DuckDB 的 ART 索引与 MySQL InnoDB 的 B+tree 索引在设计上存在比较明显的差异, 这是行存引擎和列存引擎的索引需求差异导致的:
ART 的设计面向内存, 适合内存数据库和 OLAP 场景; B+tree 适合磁盘数据库和 OLTP 场景. InnoDB 发展多年, MySQL 经历几次大版本的重构, 在 InnoDB 整体性能多次迭代的情况下, 其 B+tree 整体的工程实现都较 ART 更为复杂.
LLM 辅助编程与检索已能高效覆盖「逐行读懂片段」的需求, 源码类文章更合适的重心是结构、调用链与设计取舍, 而非替代阅读器复述每一行. 开篇因此只保留一句过渡, 把方法论收在此处, 避免打断正文读者的工程阅读节奏.