InnoDB 事务锁调度分析
准备
MySQL 8.0.25
背景
数据库内核月报 InnoDB 事务锁系统简介对 InnoDB 的事务锁系统: record lock 和 table lock 做了具体的介绍, 而 InnoDB 事务 sharded 锁系统优化 介绍了 MySQL 官方团队针对 InnoDB 事务锁系统进行的拆分优化. InnoDB 采用 2PL + MVCC 的并发控制方式, 以此来提高读写性能. 两阶段加锁(2PL)将事务锁的申请与释放拆为两步: 1.在事务过程中统一加锁, 2. 在事务提交或回滚后统一放锁, 除非事务提交或者回滚, 否则不会在事务的中间状态释放锁. 所以在事务申请 lock 的过程中, 需要判断是否与其他事务持有的 lock 冲突, 对于冲突情况需要进入 waiting 队列, 而在持有 lock 的事务提交或者回滚之后, 都会释放持有的事务锁, 从而选择等待队列里的事务进行 grant lock. 选择合适的等待事务可以有效的提高事务的并发性能, 所以事务锁调度算法的关键是如何选择合适的等待事务. 当存在多个事务请求同一个对象的锁时, 哪个事务, 或者哪些事务应当最先获得锁?
First Come First Served (FCFS)
在 8.0.3 之前的 MySQL 版本, 采用的是 FCFS 的调度算法, 原理也相对简单. 在事务执行阶段向对应的 record 进行加锁行为, 通过 lock_sys 记录的 record lock 来判断是否存在冲突, 因为两阶段加锁的限制, 对于冲突的 lock 我们将其放入等待队列, 当持有的事务提交或者回滚时, 逐一释放其持有的 lock时, 会检查相应的等待队列,并按 FCFS 顺序检查是否可以将锁授予等待事务.
Contention-Aware Transaction Scheduling (CATS)
CATS 的全称是 Contention-Aware Transaction Scheduling (竞争感知), 在 MySQL 8.0.20 开始已经作为默认的事务调度算法, 不仅仅只在低冲突场景才会使用. 事务锁调度最常见的策略就是 FCFS 策略, 先到先得, 这种朴素的调度策略实现也较为简单, 但存在的问题是例如某个等待事务持有较多的 lock 并且阻塞了其他的事务的进行,但因为先到先得的策略无法立即获得 lock, 从而致使整个数据库的 TPS 减慢. 这是 FCFS 策略无法解决的问题, 所以我们最好对事务本身进行感知, 比如所有事务的等待关系等. CATS 相关的论文有两篇: Identifying the Major Sources of Variance in Transaction Latencies: Towards More Predictable Databases, Contention-Aware Lock Scheduling for Transactional Databases.
论文[Contention-Aware Lock Scheduling for Transactional Databases]介绍了几种调度策略, 并逐步引申出 CATS 算法.
- Number of locks held
在 FCFS 策略后, 我们可以讨论以锁持有的数量来判断优先级, 例如下图:
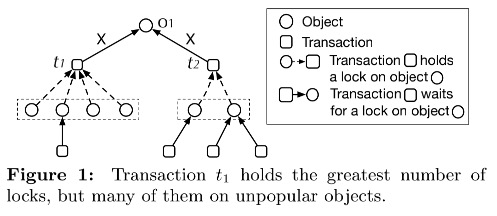
事务 t1 和事务 t2 都在等待对象 O1 的锁, t1 事务本身持有的锁数量是 4 个, 而 t2 事务持有的锁数量是 2 个, 假如以"锁持有的数量"为标准, 那事务 t2 应该获得 lock, 但在事务的等待关系中, 有 3 个事务等待在 t2 上,而仅有 1 个事务等待在 t1.
- Number of locks that block other transactions
假定以等待事务阻塞事务数量来判断优先级, 例如下图:
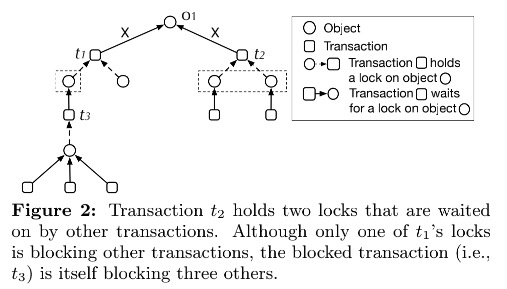
事务 t1 和事务 t2 都在等待对象 O1 的锁, t1 事务持有的锁只有一个阻塞了事务 t3, 而 t2 事务持有的锁却阻塞了两个事务, 假如以等待事务阻塞的事务数量来判断优先级, O1 的锁会被授予 t2, 但需要注意的是 t3 事务却阻塞了 3 个其他事务. 所以假如我们想提高事务的并发度, 最好的选择是将 O1 锁授予 t1.
- Depth of the dependency subgraph
假定以等待事务关系图的深度来判断优先级, 例如下图:
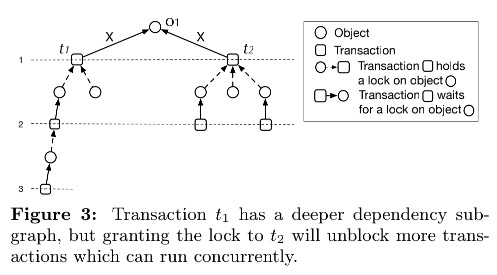
虽然 t1 事务有更深的依赖关系, 而 t2 事务同时阻塞两个事务, 但假如将锁授予 t1, 势必影响整个 DB 的事务并发度.
- Largest-Dependency-Set-First (LDSF)
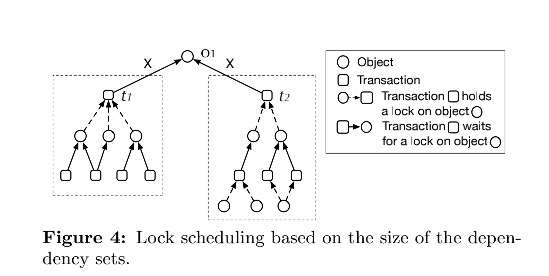
真正的事务等待关系应该是有向图, 所以计算权重不应该考虑子树, 而是子图. 所以最后提出了一种 Largest-Dependency-Set-First (LDSF) 的算法, 根据计算等待事务所有的等待关系权重来决定锁的调度优先级.
InnoDB 根据 LDSF 在原有的事务锁基础上实现了基于竞争感知的事务锁调度算法, 主要两个 patch 分别是 WL#10793: InnoDB: Use CATS for scheduling lock release under high load, WL#13468: Improved CATS implementation.
源码分析
MySQL 8.0.18 版本针对死锁检测进行了优化, 将原先的死锁检测机制交由 background thread: lock_wait_timeout_thread() 来处理, 思路是将当前的事务锁 lock 信息打一份快照, 由这份快照判断是否存在回环, 假如存在死锁即唤醒等待事务. 因为这个过程可以感知所有的锁等待关系, 所以 InnoDB 也基于这份快照来计算权重.
lock_wait_timeout_thread 线程除了检查等待超时以外, 也会更新全局等待事务的权重和死锁检测, 具体的函数是 lock_wait_update_schedule_and_check_for_deadlocks():
static void lock_wait_update_schedule_and_check_for_deadlocks() {
/* ... */
ut::vector<waiting_trx_info_t> infos; /* 记录事务的依赖关系. */
ut::vector<int> outgoing;
ut::vector<trx_schedule_weight_t> new_weights; /* 记录事务的权重. */
/* 获取事务的等待关系, 仅收集等待事务, 即 [from] 事务阻塞在 [to] 事务上. */
auto table_reservations = lock_wait_snapshot_waiting_threads(infos);
/* 构建事务的等待关系图.
* outgoing 数组的下标代表是第 n 个事务, value 代表其等待的事务下标. */
lock_wait_build_wait_for_graph(infos, outgoing);
/* We don't update trx->lock.schedule_weight for trxs on cycles. */
lock_wait_compute_and_publish_weights_except_cycles(infos, table_reservations,
outgoing, new_weights);
if (innobase_deadlock_detect) {
/* 假如打开了死锁检测, 处理死锁的情况. */
/* This will also update trx->lock.schedule_weight for trxs on cycles. */
lock_wait_find_and_handle_deadlocks(infos, outgoing, new_weights);
}
}在获取了所有的等待事务关系图后,需要根据其阻塞的事务数量开始计算权重, 过程如下:
- lock_wait_compute_initial_weights(): 初始化权重, 初始值为 1. InnoDB 新增了一个全局自增变量 lock_wait_table_reservations, 在每个线程因为锁等待进入等待状态时, 会获取当时的 lock_wait_table_reservations 的值, 所以每个事务自身的 table_reservations 与全局的 lock_wait_table_reservations 的差值代表了等待的时间, 差值越大等待时间越长. 所以在事务锁的调度算法中, 为了防止有事务饿死的情况, 将差值超过等待事务数量的事务权重设为等待事务数量:
/* WEIGHT_BOOST 设置成等待事务的数量或者 1e9. */
const trx_schedule_weight_t WEIGHT_BOOST =
n == 0 ? 1 : std::min<trx_schedule_weight_t>(n, 1e9 / n);
new_weights.clear();
/* 默认权重值为 1. */
new_weights.resize(n, 1);
/* MAX_FAIR_WAIT 是两倍的等待事务数量. */
const uint64_t MAX_FAIR_WAIT = 2 * n;
for (size_t from = 0; from < n; ++from) {
/* reservation_no 是事务进入等待状态时的 lock_wait_table_reservations 的值,
* table_reservations 是开始进行快照时 lock_wait_table_reservations 的值,
* 所以假如 infos[from].reservation_no + MAX_FAIR_WAIT 小于 table_reservations
* 的情况出现就代表事务 "from" 等待的时间较长, 为了防止饿死, 所以将其权重置为
* 两倍的等待事务数量(n). */
if (infos[from].reservation_no + MAX_FAIR_WAIT < table_reservations) {
new_weights[from] = WEIGHT_BOOST;
}
}-
lock_wait_compute_incoming_count(): 更新事务等待关系图中的入度情况, 即一个事务阻塞了多少个事务.
-
lock_wait_accumulate_weights(): 计算每个等待事务的权重, 其策略是累加等待事务阻塞的事务权重, 例如事务 t1 阻塞了事务 t2, t3, t5, 则 t1 事务的权重为:
t1_weight = t1_weight + t2_weight + t3_weight + t5_weight;- lock_wait_publish_new_weights(): 更新等待事务权重.
事务在提交或者回滚之后都会释放其持有的 lock: lock_release(). 将其持有的锁授予哪个事务的顺序是, 第一顺位是高优先级的事务, 其次是事务的权重排序, 权重为 1 或者 0 ( lock.schedule_weight 的默认值)的事务依照 FCFS 的顺序.
总结
本文介绍了 InnoDB 在锁调度策略的最新优化, 该算法在锁冲突严重的场景效果明显, 计算权重的重要参考指标是等待事务的等待时间 (lock_wait_table_reservations) 和其阻塞的事务权重之和. InnoDB 目前的实现没有区分读/写事务, 例如当多个读事务等待同一个锁, 选择读事务较多的子图, 可以有效的提高事务并发度. 关于 CATS 的策略方面后续可以加入更多的指标, 在计算的复杂度和判断的有效性采用折中的方案, 既不影响权重的计算, 也有效的提高数据库的事务并发度.